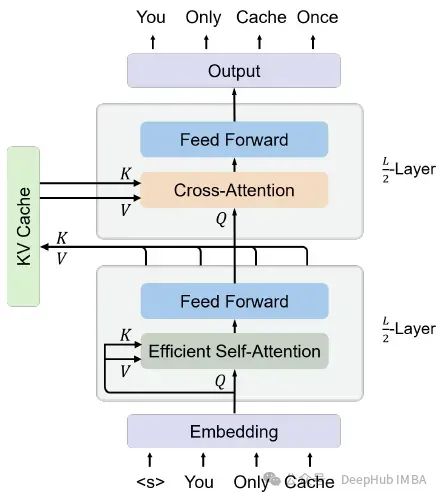
You Only Cache Once:YOCO 基于Decoder-Decoder 的一个新的大语言模型架构
这是微软再5月刚刚发布的一篇论文提出了一种解码器-解码器架构YOCO,因为只缓存一次KV对,所以可以大量的节省内存。 以前的模型都是通过缓存先前计算的键/值向量,可以在当前生成步骤中重用它们。键值(KV)缓存避免了对每个词元再次编码的过程,这样可以大大提高了推理速度。 但是随着词元数量的增加,KV缓...

【大模型】在大语言模型的架构中,Transformer有何作用?
Transformer在大语言模型架构中的作用 Transformer是一种用于序列到序列(Seq2Seq)任务的深度学习模型,由Vaswani等人于2017年提出。在大语言模型(LLM)的架构中,Transformer扮演着关键的角色,它作为模型的核心组件,负责处理文本序列的建模和处...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐

社区圈子




最佳实践




