
Spark编程语言选择:Scala、Java和Python
在大数据处理和分析领域,Apache Spark已经成为一种非常流行的工具。它提供了丰富的API和强大的性能,同时支持多种编程语言,包括Scala、Java和Python。选择合适的编程语言可以直接影响Spark应用程序的性能、可维护性和开发效率。在本文中,我们将详细探讨每种编程语言,并提供示例代码...
[AIGC ~大数据] 深入理解Hadoop、HDFS、Hive和Spark:Java大师的大数据研究之旅
作为一位Java大师,我始终追求着技术的边界,最近我将目光聚焦在大数据领域。在这个充满机遇和挑战的领域中,我深入研究了Hadoop、HDFS、Hive和Spark等关键技术。本篇博客将从"是什么"、"为什么"和"怎么办"三个角度,系统地介绍这些技术。是什么?HadoopHadoop是一个开源的分布式...

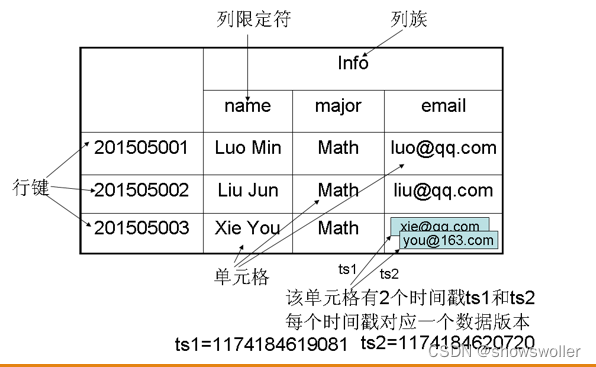
【大数据技术Hadoop+Spark】HBase数据模型、Shell操作、Java API示例程序讲解(附源码 超详细)
一、HBase数据模型HBase分布式数据库的数据存储在行列式的表格中,它是一个多维度的映射模型,其数据模型如下所示。表的索引是行键,列族,列限定符和时间戳,表在水平方向由一个或者多个列族组成,一个列族中可以包含任意多个列,列族支持动态扩展,可以很轻松的添加一个列族或者列,无须预先定义列的数量及数据...
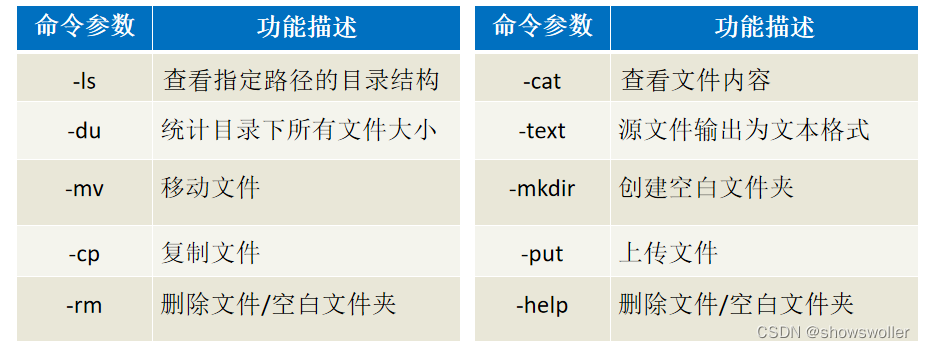
【大数据技术Hadoop+Spark】HDFS Shell常用命令及HDFS Java API详解及实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留言私信~~~一、HDFS的Shell介绍Shell在计算机科学中俗称“壳”,是提供给使用者使用界面的进行与系统交互的软件,通过接收用户输入的命令执行相应的操作,Shell分为图形界面Shell和命令行式Shell。文件系统(FS)Shell包含了各种的类Shell的命...
请问大数据计算MaxCompute提交spark任务为什么突然遇到java.这个报错?
请问大数据计算MaxCompute提交spark任务为什么突然遇到java.net.UnknownHostException这个报错?这个任务之前还能正常运行的
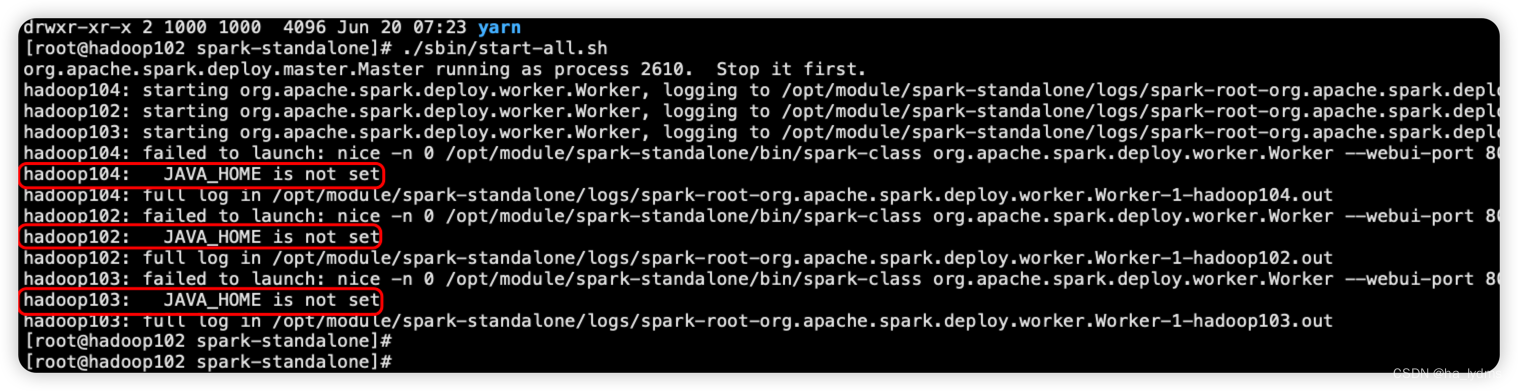
Spark 启动时,报JAVA_HOME is not set
1、报错内容Spark启动时报错:hadoop104: JAVA_HOME is not set2、解决方式解决方式:打开启动配置文件cd /opt/module/spark-standalone/sbin/ vim spark-config.sh配置Java的环境变量#JAVA_HOME expo...
大数据计算MaxCompute spark Java任务里 为什么在生产环境下报这个错误的?
大数据计算MaxCompute spark Java任务里 为什么在生产环境下报这个错误的?而在本地运行,冒烟测试都是没问题的, 这个怎么解决的?ERROR org.apache.spark.deploy.yarn.ApplicationMaster - User class threw excep...
DataWorks中spark Java任务里 为什么在生产环境下报这个错误的?
DataWorks中spark Java任务里 为什么在生产环境下报这个错误的?而在本地运行,冒烟测试都是没问题的,怎么解决?ERROR org.apache.spark.deploy.yarn.ApplicationMaster - User class threw exception: java...
ALS算法 java spark rdd简单实现
import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api...
JAVA Spark rdd使用Spark编程实现:统计出每个省份广 告被点击次数的TOP3
假设这些信息都存存储在一个文件里时间数 省份 城市 用户 广告如下所示:(中间字段使用空格隔开)import java.util.ArrayList; import java.util.Arrays; import java.util.Collections; import java.util.L...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark Hadoop
- apache spark数据
- apache spark分析
- apache spark Python
- apache spark可视化
- apache spark数据处理
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark SQL
- apache spark streaming
- apache spark Apache
- apache spark rdd
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark实战
- apache spark机器学习
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作