
Spark【环境搭建 01】spark-3.0.0-without 单机版(安装+配置+测试案例)
我使用的安装文件是 spark-3.0.0-bin-without-hadoop.tgz ,以下内容均以此版本进行说明。使用 without 版本的安装包要进行 spark 和 hadoop 的关联配置【hadoo的版本是3.1.3】。 1.1 解压 我使用的是之前下载的安装包,也可以去官网下载,选...
Spark_Day07:Spark SQL(DataFrame是什么和数据分析(案例讲解))
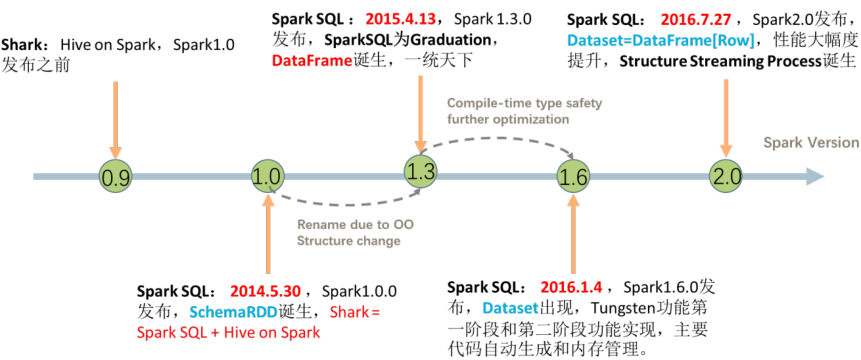
02-[了解]-内容提纲主要2个方面内容:DataFrame是什么和数据分析(案例讲解)1、DataFrame是什么 SparkSQL模块前世今生、官方定义和特性 DataFrame是什么 DataFrame = RDD[Row] + Schema,Row表示每行数据,抽象的,并不知道每行Row数据...

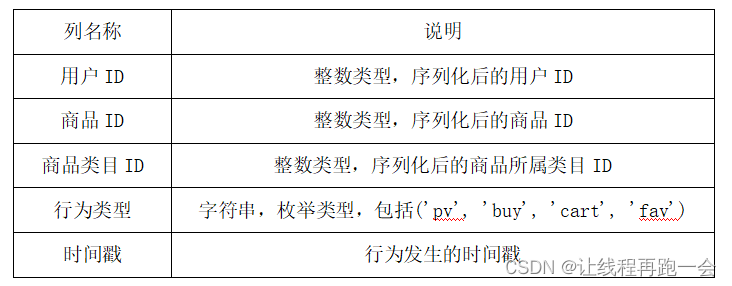
Spark SQL案例【电商购买数据分析】
数据说明Spark 数据分析 (Scala)import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, SparkSession} import org.apache.spark.{SparkConf, S...

Spark【RDD编程(四)综合案例】
案例1-TOP N个数据的值输入数据:1,1768,50,155 2,1218,600,211 3,2239,788,242 4,3101,28,599 5,4899,290,129 6,3110,54,1201 7,4436,259,877 8,2369,7890,27处理代码:def main(...
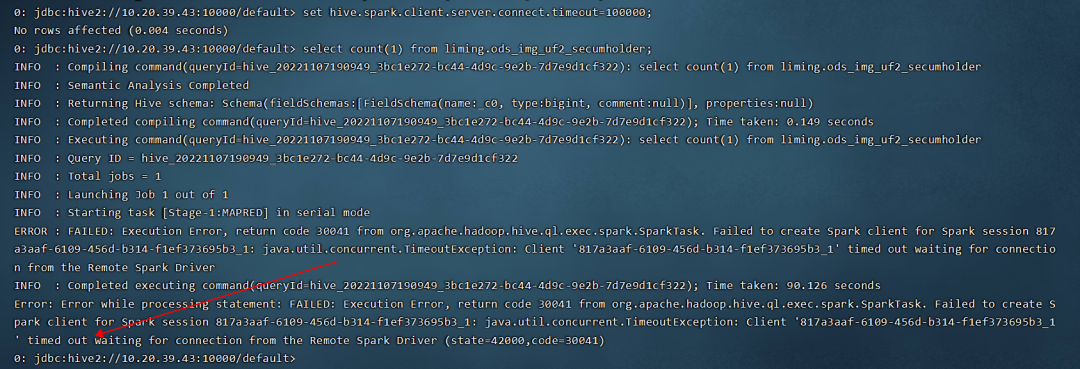
线上 hive on spark 作业执行超时问题排查案例分享
线上 hive on spark 作业执行超时问题排查案例分享大家好,在此分享一个某业务系统的线上 hive on spark 作业在高并发下频现作业失败问题的原因分析和解决方法,希望对大家有所帮助。1 问题现象某业务系统中,HIVE SQL 以 hive on spark 模式运行在 yarn上指...
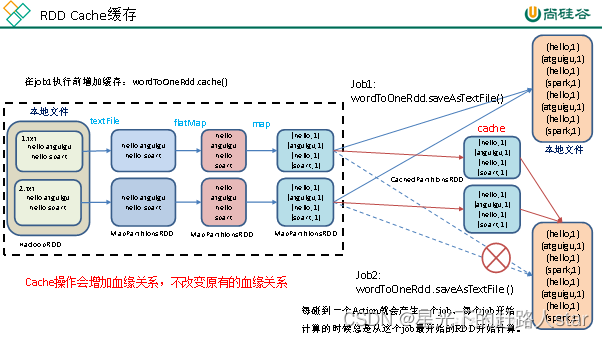
Spark学习--3、WordCount案例、RDD序列化、RDD依赖关系、RDD持久化(二)
4、RDD持久化4.1 RDD Cache缓存1、RDD Cache缓存(1)RDD通过Cache或者persist方法将前面的计算结果缓存(2)默认情况下会把数据以序列化的形式缓存在JVM的堆内存中。(3)但是并不是这个两个方法被调用时立即缓存,而是触发后面的action算子时,该R...
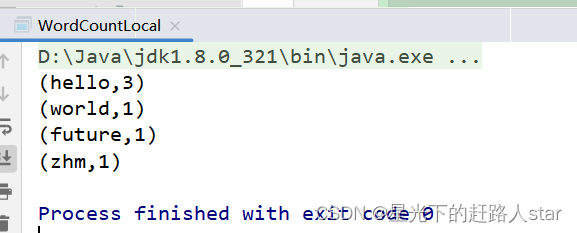
Spark学习--3、WordCount案例、RDD序列化、RDD依赖关系、RDD持久化(一)
1、WordCount案例实操导入项目依赖<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</art...

基于Spark的案例:同义词识别
一、业务场景在机器学习中,有时会遇到同义词识别问题。现需要使用Spark ML库来解决同义词识别问题。二、数据集说明本案例所使用的数据集为纯文本文件,说明如下: 数据集路径:/data/dataset/ml/synonymous.txt三、操作步骤阶段一、启动HDFS、Spark集群服务和zepp...
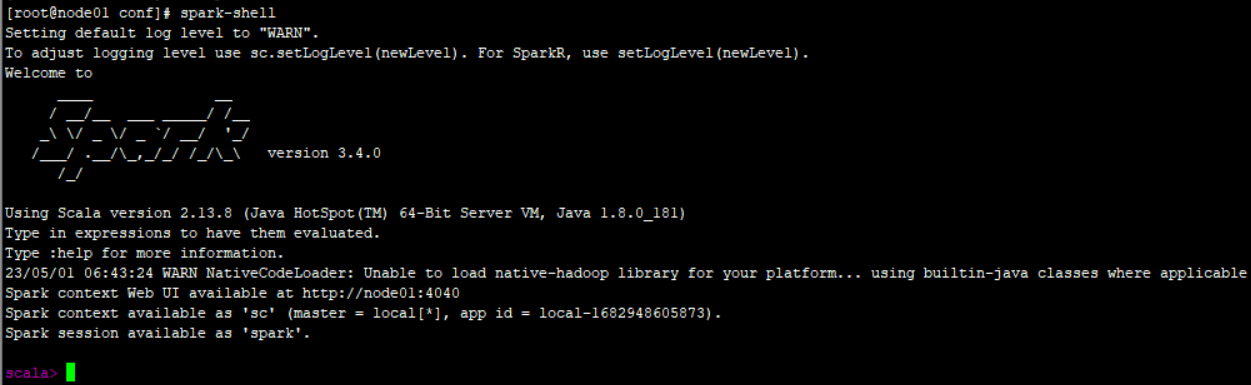
Spark入门以及wordcount案例代码
文章目录spark概念1.spark安装配置1.1 解压环境配置1.2 设置spark运行环境和配置参数1.3 简单的测试2.快速开始2.1 引入依赖2.2 实现wordcount2.3 测试spark概念Apache Spark是用于大规模数据处理的统一分析引擎。它提供了Java、Scala、Py...

Spark案例读取不同格式文件以及读取输入数据存入Mysql
文章目录1.spark读取文件1.txt文件代码测试2.csv文件代码测试3.读取json文件源码测试2.读取输入的数据存入mysqlmysql创建一张表代码测试1.spark读取文件1.txt文件代码 def main(args: Array[String]): Unit = { &nb...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark Hadoop
- apache spark数据
- apache spark分析
- apache spark Python
- apache spark可视化
- apache spark数据处理
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark SQL
- apache spark streaming
- apache spark Apache
- apache spark rdd
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作