
Uber基于Apache Hudi增量 ETL 构建大规模数据湖
Uber 的全球数据仓库团队使用统一的、 PB 级、集中建模的数据湖使所有 Uber 的数据民主化。数据湖由使用维度数据建模技术[1]开发的基础事实、维度和聚合表组成,工程师和数据科学家可以自助方式访问这些表,为 Uber 的数据工程、数据科学、机器学习和报告提供支持。因此,计算这些表的 ETL(提...

基于 Apache Flink Table Store 的全增量一体实时入湖
基于 Apache Flink Table Store 的全增量一体实时入湖本文简要回顾了数据入湖(仓)的发展阶段,针对在数据库数据入湖中面临的问题,提出了使用 Flink Table Store 作为全增量一体入湖的解决方案,并辅以开源 Demo ...

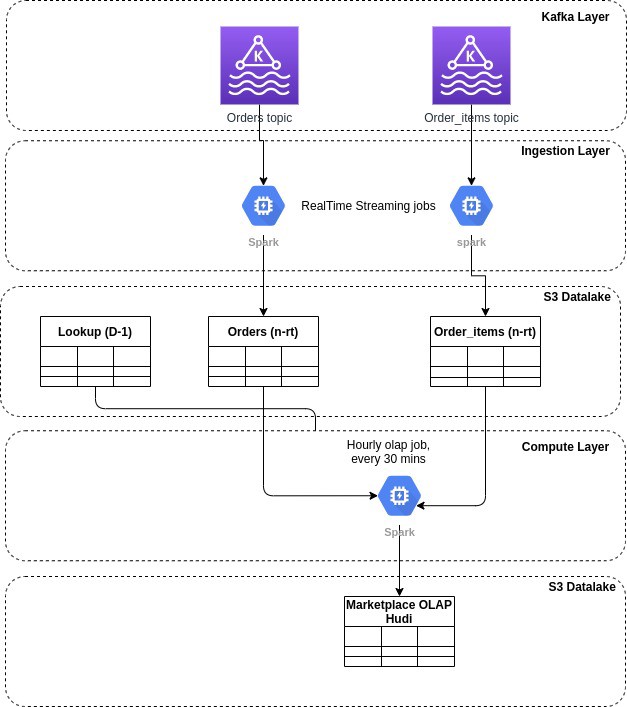
基于 Apache Hudi 构建增量和无限回放事件流的 OLAP 平台
1. 摘要在本博客中,我们将讨论在构建流数据平台时如何利用 Hudi 的两个最令人难以置信的能力。增量消费--每 30 分钟处理一次数据,并在我们的组织内构建每小时级别的OLAP平台事件流的无限回放--利用 Hudi 的提交时间线在超级便宜的云对象存储(如 AWS S3)中存储 10 天的事件流(想...
Apache Flink - 增量检查点 - CP的意外大小
"是什么原因导致一些CP节省了预期的大小(大约500kB),有些CP的大小在整个当前管理状态大小附近,即使负载是恒定的?使用增量检查点时,lastCheckpointSize指标的确切测量结果是什么?"
Apache Kylin权威指南3.3 触发增量构建
3.3 触发增量构建 3.3.1 Web GUI触发 在Web GUI上触发Cube的增量构建与触发全量构建的方式基本相同。在Web GUI的Model页面中,选中想要增量构建的Cube,单击Action→Build,如图3-3所示。 不同于全量构建,增量构建的Cube会在此时弹出对话框让用户选择“...
Apache Kylin权威指南3.2 设计增量Cube
3.2 设计增量Cube 3.2.1 设计增量Cube的前提 并非所有的Cube都适用于增量构建,Cube的定义必须包含一个时间维度,用来分割不同的Segment,我们将这样的维度称为分割时间列(Partition Date Column)。尽管由于历史原因该命名中存在“date”的字样,但是分割时...
Apache Kylin权威指南3.1 为什么要增量构建
第3章 增量?构建 第2章介绍了如何构建Cube并利用其完成在线多维分析的查询。每次Cube的构建都会从Hive中批量读取数据,而对于大多数业务场景来说,Hive中的数据处于不断增长的状态。为了支持Cube中的数据能够不断地得到更新,且无需重复地为已经处理过的历史数据构建Cube,因此对于Cube引...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子







Apache您可能感兴趣
- Apache负载
- Apache阿里云
- Apache数据库
- Apache服务器
- Apache请求
- Apache入门
- Apache tomcat
- Apache web
- Apache pdf
- Apache文本
- Apache flink
- Apache配置
- Apache rocketmq
- Apache安装
- Apache php
- Apache dubbo
- Apache linux
- Apache spark
- Apache开发
- Apache报错
- Apache服务
- Apache微服务
- Apache从入门到精通
- Apache hudi
- Apache doris
- Apache mysql
- Apache日志
- Apache kafka