
Flink(一)【WordCount 快速入门】
前言 学完了 Hadoop、Spark,本想着先把 Kafka、Flume 这些工具先学完的,但想了想还是把核心的技术先学完最后再去把那些工具学学。 最近心有点累哈哈哈,偷偷立个 f...

想了解流计算,你必须得看一眼,实现Flink on Yarn的三种部署方式,并运行wordcount
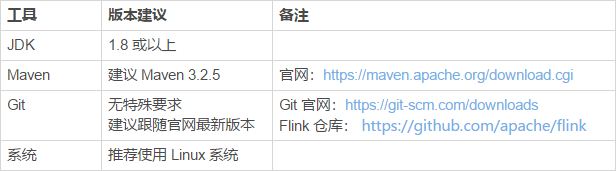
1. 第一种方式:YARN session1.1 说明1.1.1 yarn-session.sh(开辟资源)+flink run(提交任务)这种模式下会启动yarn session,并且会启动Flink的两个必要服务:JobManager和Task-managers,然后你可以向集群提交作业。同一个...

Flink 入门程序 WordCount 和 SQL 实现
我们右键运行时相当于在本地启动了一个单机版本。生产中都是集群环境,并且是高可用的,生产上提交任务需要用到flink run 命令,指定必要的参数。本课时我们主要介绍 Flink 的入门程序以及 SQL 形式的实现。上一课时已经讲解了 Flink 的常用应用场景和架构模型设计,这一课时我们将会从一个最...
请问假如在流式的wordcount里我想统计从开始到结束所有单词数,可以通过定义一个简单#Flink
请问假如在流式的wordcount里我想统计从开始到结束所有单词数,可以通过定义一个简单的Java map实现吗?是否会因为分布式而存在数据缺失的情况 #Flink
运行flink自带的wordcount例子 报错 缺少jar 这个能指定吗?#Flink
运行flink自带的wordcount例子 报错 缺少jar 这个能指定吗?#Flink
flink on yarn 执行wordCount报异常:找不到或不能加载主类
20/02/08 23:49:58 INFO client.RMProxy: Connecting to ResourceManager at hadoop1/192.168.0.111:8032 Container: container_1581176588427_0001_01_000001 o...
第一个flink的WordCount程序运行时错误,
错误:Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/flink/streaming/api/environment/StreamExecutionEnvironmentat test.FlinkTest.m...
Flink单机版安装与wordCount
Flink为大数据处理工具,类似hadoop,spark.但它能够在大规模分布式系统中快速处理,与spark相似也是基于内存运算,并以低延迟性和高容错性主城,其核心特性是实时的处理流数据。从此大数据生态圈又再填一员。。。具体详解,还要等之后再分享,这里就先简要带过~ Fl...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子




最佳实践
更多




实时计算 Flink版您可能感兴趣
- 实时计算 Flink版并行度
- 实时计算 Flink版数据
- 实时计算 Flink版回滚
- 实时计算 Flink版同步
- 实时计算 Flink版批处理
- 实时计算 Flink版任务
- 实时计算 Flink版作业
- 实时计算 Flink版合流
- 实时计算 Flink版窗口
- 实时计算 Flink版算子
- 实时计算 Flink版报错
- 实时计算 Flink版oracle
- 实时计算 Flink版版本
- 实时计算 Flink版表
- 实时计算 Flink版配置
- 实时计算 Flink版设置
- 实时计算 Flink版 CDC
- 实时计算 Flink版模式
- 实时计算 Flink版运行
- 实时计算 Flink版数据库
- 实时计算 Flink版连接
- 实时计算 Flink版库
- 实时计算 Flink版全量
- 实时计算 Flink版参数
- 实时计算 Flink版集群
- 实时计算 Flink版日志