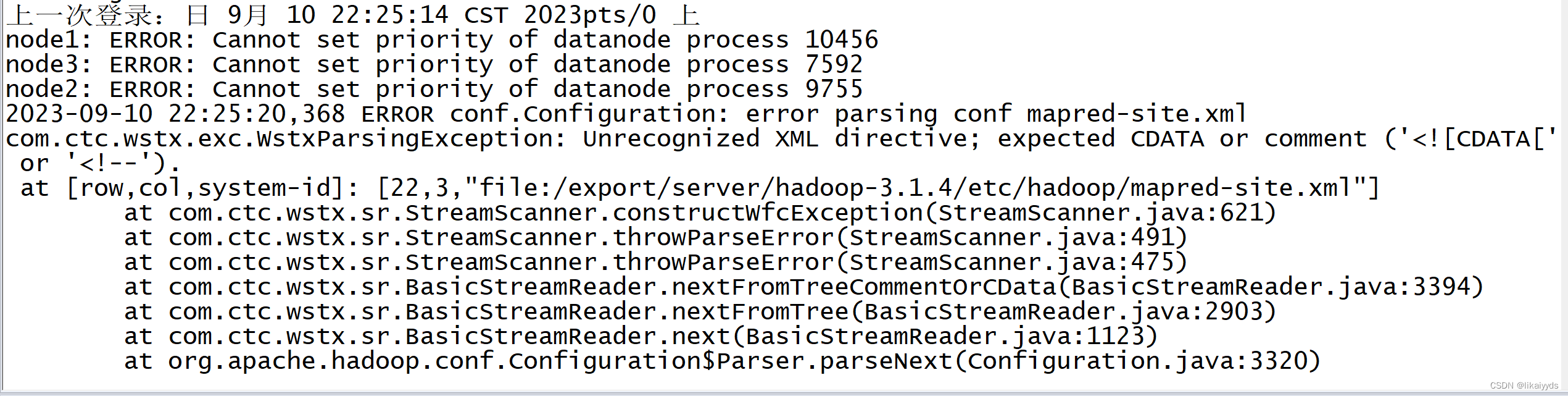
关于hadoop报错ERROR: Cannot set priority of namenode process与jps仅有自身的某类解决办法
运行start-sh.all发现了如图的问题也是搞了很久搜了很多教程,发现很多人并不是大毛病而是很多小细节出了错误。首先检查如下hadoop-env.sh ,core-site.xml ,hdfs-site.xml ,mapred-site.xml ,yarn-site.xml内容是否有配置错误下图...
Hadoop jps正确使用流程及报错处理
1.模拟主机宕机[root@hadoop000 ~]# jps 4868 DataNode 5062 SecondaryNameNode 5256 Jps 4717 NameNode [root@hadoop000 ~]# kill -9 $(pgrep -f hadoop-2.8.1) [root...

Hadoop中运行jps命令检验,m3、m4、m5上多了Journal的操作步骤以及代码分别是什么?
Hadoop中运行jps命令检验,m3、m4、m5上多了Journal的操作步骤以及代码分别是什么?
Hadoop中成功启动之后,jps 命令的作用是什么呢?
Hadoop中成功启动之后,jps 命令的作用是什么呢?
在Hadoop中使用jps命令有什么用?
jps命令用于检查Hadoop守护程序是否正常运行。此命令显示在计算机上运行的所有守护程序,即Datanode,Namenode,NodeManager,ResourceManager等。
hadoop集群运行jps命令以后Datanode节点未启动的解决办法
出现该问题的原因:在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而datanode的clusterID 保持不变。 1:其实网上已经有解决办法了,这里自己脑补一下,也可以...
hadoop2.5.2 启动成功后,用jps查看节点:发现少了DataNode
使用less ~/hadoop-2.5.2/logs/hadoop-zkpk-datanode-pxe01.log 查看日志得知: datanode的clusterID 和 namenode的clusterID 不匹配。 解决办法: 1.找到 ~/hadoopdata/dfs/name/curren...
误删/tmp导致hadoop无法启停, jps无法查看的解决方法
问题描述 我的hadoop版本是hadoop-cdh4.2.0,由于误删了/tmp目录(不是hadoop.tmp.dir设定的那个目录),在Namenode,SecondaryNamenode和Datanode上使用jps无法查看到如下结果: [root@desktop1 ~]# jps 5389 ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








