Hadoop学习:MapReduce不使用Reduce将表合并提高效率
一、✌题目要求record表:ID城市编号空气指数001032450020265500305743004042460050295600601637007058310080368300902349city表:城市编号城市名称01长沙02株洲03湘潭04怀化05岳阳目标表:ID城市名称空气指数001湘潭...
Hadoop学习:MapReduce实现两张表合并
一、✌题目要求record表:ID城市编号空气指数001032450020265500305743004042460050295600601637007058310080368300902349city表:城市编号城市名称01长沙02株洲03湘潭04怀化05岳阳目标表:ID城市名称空气指数001湘潭...
Hadoop MapReduce 保姆级吐血宝典,学习与面试必读此文!(三)
8. Map端实现 JOIN8.1 概述适用于关联表中有小表的情形.使用分布式缓存,可以将小表分发到所有的map节点,这样,map节点就可以在本地对自己所读到的大表数据进行join并输出最终结果,可以大大提高join操作的并发度,加快处理速度8.2 实现步骤先在mapper类中预先定义好小表,进行j...

Hadoop MapReduce 保姆级吐血宝典,学习与面试必读此文!(二)
6. MapReduce的运行机制详解6.1 MapTask 工作机制整个Map阶段流程大体如上图所示。简单概述:inputFile通过split被逻辑切分为多个split文件,通过Record按行读取内容给map(用户自己实现的)进行处理,数据被map处理结束之后交给OutputCollector...
Hadoop MapReduce 保姆级吐血宝典,学习与面试必读此文!(一)
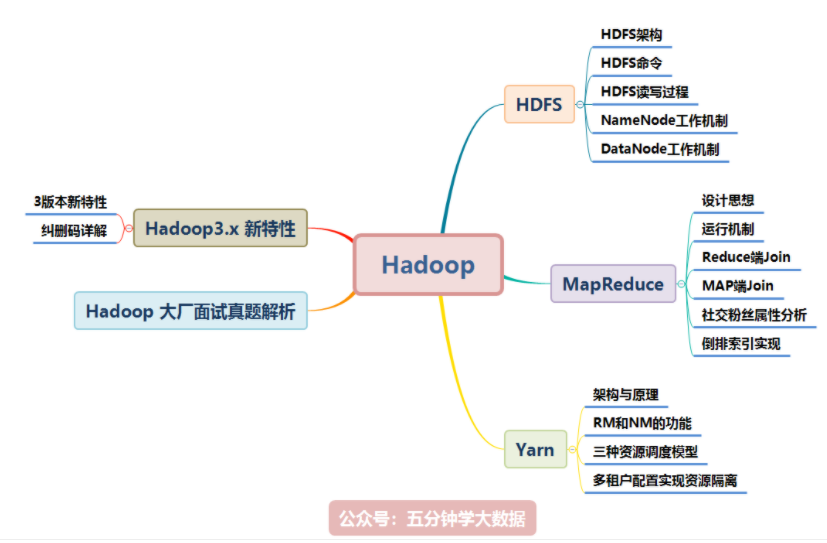
Hadoop 涉及的知识点如下图所示,本文将逐一讲解:本文档参考了关于 Hadoop 的官网及其他众多资料整理而成,为了整洁的排版及舒适的阅读,对于模糊不清晰的图片及黑白图片进行重新绘制成了高清彩图。目前企业应用较多的是Hadoop2.x,所以本文是以Hadoop2.x为主,对于Hadoop3.x新...
案例学习:MapReduce
案例学习:MapReduce
Hadoop学习(4)-mapreduce的一些注意事项
Hadoop学习(4)-mapreduce的一些注意事项
一脸懵逼学习Hive的安装(将sql语句翻译成MapReduce程序的一个工具)
Hive只在一个节点上安装即可: 1.上传tar包:这个上传就不贴图了,贴一下上传后的,看一下虚拟机吧: 2.解压操作: [root@slaver3 hadoop]# tar -zxvf hive-0.12.0.tar.gz 解压后贴一下图: 3:解压缩以后启动一下hive: ...
一脸懵逼学习Hadoop中的MapReduce程序中自定义分组的实现
1:首先搞好实体类对象: write 是把每个对象序列化到输出流,readFields是把输入流字节反序列化,实现WritableComparable,Java值对象的比较:一般需要重写toString(),hashCode(),equals()方法 1 package com.areapart...
一脸懵逼学习Hadoop中的序列化机制——流量求和统计MapReduce的程序开发案例——流量求和统计排序
一:序列化概念 序列化(Serialization)是指把结构化对象转化为字节流。反序列化(Deserialization)是序列化的逆过程。即把字节流转回结构化对象。Java序列化(java.io.Serializable) 二:Hadoop序列化的特点 (1):序列化格式特点: 紧凑:高效使用...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子

开源大数据平台 E-MapReduce学习相关内容
开源大数据平台 E-MapReduce您可能感兴趣
- 开源大数据平台 E-MapReduce访问
- 开源大数据平台 E-MapReduce报错
- 开源大数据平台 E-MapReduce实践
- 开源大数据平台 E-MapReduce ecs
- 开源大数据平台 E-MapReduce服务器
- 开源大数据平台 E-MapReduce集群
- 开源大数据平台 E-MapReduce emr
- 开源大数据平台 E-MapReduce机器
- 开源大数据平台 E-MapReduce任务
- 开源大数据平台 E-MapReduce信息
- 开源大数据平台 E-MapReduce hadoop
- 开源大数据平台 E-MapReduce数据
- 开源大数据平台 E-MapReduce编程
- 开源大数据平台 E-MapReduce maxcompute
- 开源大数据平台 E-MapReduce运行
- 开源大数据平台 E-MapReduce作业
- 开源大数据平台 E-MapReduce程序
- 开源大数据平台 E-MapReduce spark
- 开源大数据平台 E-MapReduce yarn
- 开源大数据平台 E-MapReduce框架
- 开源大数据平台 E-MapReduce排序
- 开源大数据平台 E-MapReduce wordcount
- 开源大数据平台 E-MapReduce api
- 开源大数据平台 E-MapReduce优化
- 开源大数据平台 E-MapReduce入门
- 开源大数据平台 E-MapReduce案例
- 开源大数据平台 E-MapReduce map