
MapReduce【自定义OutputFormat】
MapReduce默认的输出格式为TextOutputFormat,它的父类是FileOutputFormat,即按行来写,且内容写到一个文本文件中去,但是并不能满足我们实际开发中的所有需求,所以就需要我们自定义OutPutFormat。自定义OutPutFormat输出数据到MySQL、HBase...

MapReduce【自定义InputFormat】
MapReduce在处理小文件时效率很低,但面对大量的小文件又不可避免,这个时候就需要相应的解决方案。默认的输入格式为TextInputFormat,对于小文件,它是按照它的父类FileInputFormat的切片机制来切片的,也就是不管一个文件多小,独占一片!对于之前的wordcount案例来说&...
MapReduce【自定义分区Partitioner】
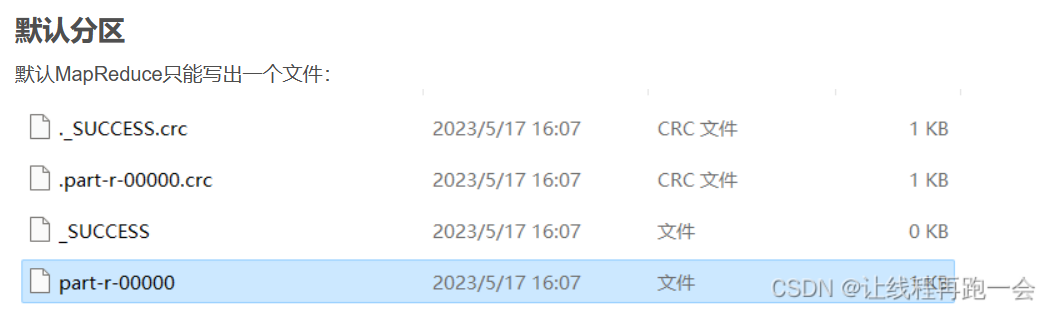
实际开发中我们可能根据需求需要将MapReduce的运行结果生成多个不同的文件,比如上一个案例【MapReduce计算广州2022年每月最高温度】,我们需要将前半年和后半年的数据分开写到两个文件中。默认分区默认MapReduce只能写出一个文件: 因为我们在提交job的时候未设置reduceTask...
MapReduce自定义分区
自定义分区很简单,主要需要以下三步: **(1)创建一个类继承抽象类 Partitioner,然后重写`getPartition()`方法。** 具体实现如下所示:public class TelePartitioner extends Partitioner<FlowBeanSo...
Hadoop中的MapReduce框架原理、Shuffle机制、Partition分区、自定义Partitioner步骤、在Job驱动中,设置自定义Partitioner、Partition 分区案例
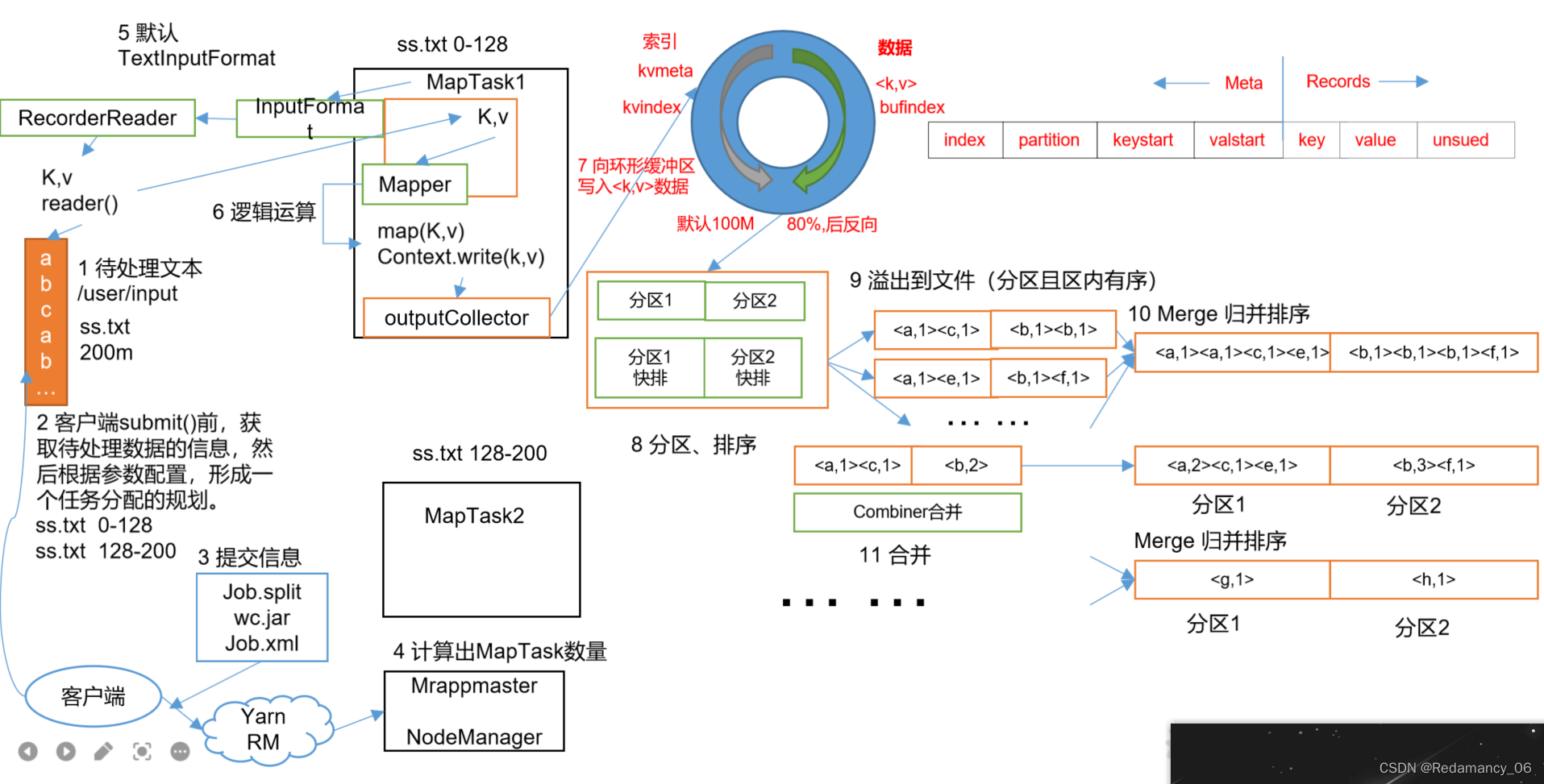
13.MapReduce框架原理13.2MapReduce工作流程上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下:(1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中(2)从内存缓冲区不断溢...
五十三、Mapreduce之自定义outputformat案例
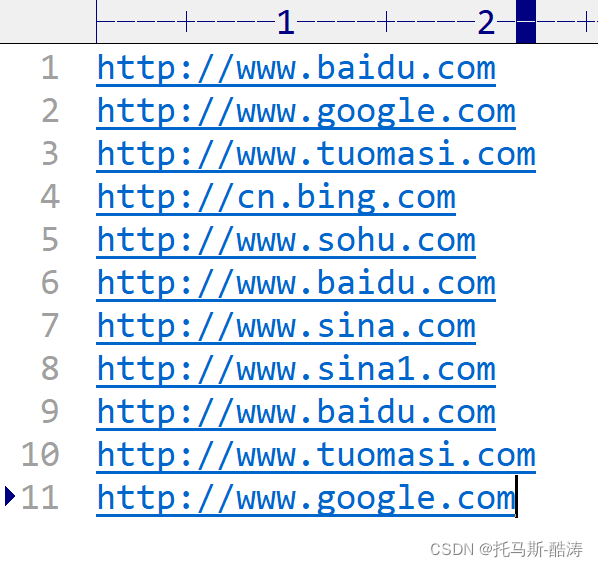
案例需求: 过滤输出的log日志,包含tuomasi的网址输出到 tuomasi.log文件,不包含 tuomasi 的网址输出到 other.log文件输入数据:期望输出数据: 注:通过观...
MapReduce中的自定义的切片规则及如何把切片分解成KV分别是什么?
MapReduce中的自定义的切片规则及如何把切片分解成KV分别是什么?
MapReduce实现与自定义词典文件基于hanLP的中文分词详解
前言: 文本分类任务的第1步,就是对语料进行分词。在单机模式下,可以选择python jieba分词,使用起来较方便。但是如果希望在Hadoop集群上通过mapreduce程序来进行分词,则hanLP更加胜任。 一、使用介绍 hanLP是一个用java语言开发的分词工具, 官网是 http...
Hadoop MapReduce编程 API入门系列之自定义多种输入格式数据类型和排序多种输出格式(十一)
自定义输入格式,将明星微博数据排序后按粉丝数 关注数 微博数 分别输出到不同文件中。 代码 1 package...
一脸懵逼学习Hadoop中的MapReduce程序中自定义分组的实现
1:首先搞好实体类对象: write 是把每个对象序列化到输出流,readFields是把输入流字节反序列化,实现WritableComparable,Java值对象的比较:一般需要重写toString(),hashCode(),equals()方法 1 package com.areapart...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子

开源大数据平台 E-MapReduce自定义相关内容
开源大数据平台 E-MapReduce您可能感兴趣
- 开源大数据平台 E-MapReduce部署
- 开源大数据平台 E-MapReduce starrocks
- 开源大数据平台 E-MapReduce workflow
- 开源大数据平台 E-MapReduce配置
- 开源大数据平台 E-MapReduce notebook
- 开源大数据平台 E-MapReduce访问
- 开源大数据平台 E-MapReduce目录
- 开源大数据平台 E-MapReduce报错
- 开源大数据平台 E-MapReduce实践
- 开源大数据平台 E-MapReduce ecs
- 开源大数据平台 E-MapReduce hadoop
- 开源大数据平台 E-MapReduce集群
- 开源大数据平台 E-MapReduce数据
- 开源大数据平台 E-MapReduce编程
- 开源大数据平台 E-MapReduce maxcompute
- 开源大数据平台 E-MapReduce运行
- 开源大数据平台 E-MapReduce作业
- 开源大数据平台 E-MapReduce程序
- 开源大数据平台 E-MapReduce spark
- 开源大数据平台 E-MapReduce yarn
- 开源大数据平台 E-MapReduce框架
- 开源大数据平台 E-MapReduce排序
- 开源大数据平台 E-MapReduce wordcount
- 开源大数据平台 E-MapReduce api
- 开源大数据平台 E-MapReduce优化
- 开源大数据平台 E-MapReduce入门
- 开源大数据平台 E-MapReduce任务
- 开源大数据平台 E-MapReduce案例
- 开源大数据平台 E-MapReduce map