【大数据技术Hadoop+Spark】Hive基础SQL语法DDL、DML、DQL讲解及演示(附SQL语句)
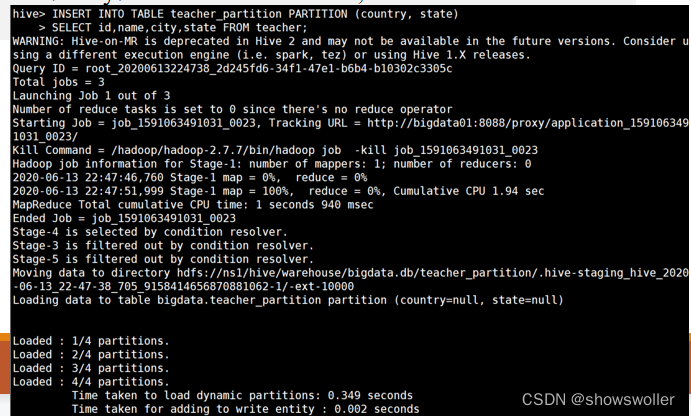
Hive基础SQL语法1:DDL操作DDL是数据定义语言,与关系数据库操作相似,创建数据库CREATE DATABASE|SCHEMA [IF NOT EXISTS] database_name显示数据库SHOW databases;查看数据库详情DESC DATABASE|SCHEMA datab...
这个flink产品是基于ak的,可以提交sql任务到ecs自建hadoop集群吗?
这个flink产品是基于ak的,可以提交sql任务到ecs自建hadoop集群吗?


《原生SQL on Hadoop引擎- Apache HAWQ 2.x最新技术解密malili》电子版地址
《原生SQL on Hadoop引擎- Apache HAWQ 2.x最新技术解密malili》原生SQL on Hadoop引擎- Apache HAWQ 2.x最新技术解密malili 电子版下载地址: https://developer.aliyun.com/ebook/2419 电子书: &...
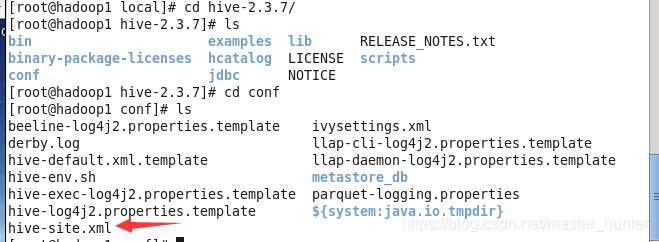
Spark SQL CLI部署CentOS分布式集群Hadoop上方法
前言配置的虚拟机为Centos6.7系统,hadoop版本为2.6.0版本,先前已经完成搭建CentOS部署Hbase、CentOS6.7搭建Zookeeper和编写MapReduce前置插件Hadoop-Eclipse-Plugin 安装。在此基础上完成了Hive详解以及CentOS下部署Hive...
[帮助文档] Dataphin即席sql报错Couldnotinitializeclassorg.apache.hadoop.hive.common.type.HiveDate
问题描述Dataphin 即席sql报错Could not initialize class org.apache.hadoop.hive.common.type.HiveDate。问题原因插入数据后,查询表报错,表结构有date字段,输入类型有问题。解决方案把表字段改成string类型,然后重新插...
入门级大数据Hadoop、Hive常用操作语法sql工作整理
大数据概念入门: Hadoop分布式文件系统,HDFS是一个高度容错性的系统,能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。 HDFS不适合用在:要求低时间延迟数据访问的应用,存储大量的小文件,多用户写入,任意修改文件。 1.客户把一个文件存入HDFS,其实HDFS会把这个文件切块...
原生SQL on Hadoop引擎- Apache HAWQ 2.x最新技术解密malili
马丽丽在2017第八届数据库大会上做了题为《原生SQL on Hadoop引擎- Apache HAWQ 2.x最新技术解密malili》的分享,就Apache HAWQ 历史,系统架构,最新功能介绍做了深入的分析。 https://yq.aliyun.com/download/458?spm=a2...
大数据框架对比:Hadoop、Storm、Samza、Spark和Flink——flink支持SQL,待看
简介 大数据是收集、整理、处理大容量数据集,并从中获得见解所需的非传统战略和技术的总称。虽然处理数据所需的计算能力或存储容量早已超过一台计算机的上限,但这种计算类型的普遍性、规模,以及价值在最近几年才经历了大规模扩展。 在之前的文章中,我们曾经介绍过有关大数据系统的常规概念、处理过程,以及各种专门术...
初体验SQL Server 2012的Hadoop连接器
本文讲的是初体验SQL Server 2012的Hadoop连接器,电影《天下无贼》中一句经典的“21世纪什么最贵?人才!”,体现了以人为本的价值观。而实际上,深处大数据时代的我们,是不是也应该幽默一回:“21世纪什么最值钱?数据!”。对于企业而言,除了人才,数据也是最重要资产之一。 “大”数据...
SQL Server+Hadoop 变身大数据解决方案
文章讲的是SQL Server+Hadoop 变身大数据解决方案,在数据库市场中,微软的SQL Server是最受关注的产品之一。在数据库知识网站DB-Engines每月公布的数据库流行度排行榜中,SQL Server几乎稳占第二名的位置。但从这个榜单每月的变化中也可以看出,大量NoSQL数据库的排...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








