
从PDF和图像中提取文本,以供大型语言模型使用
想法大型语言模型已经席卷了互联网,导致更多的人没有认真关注使用这些模型最重要的部分:高质量的数据!本文旨在提供一些有效从任何类型文档中提取文本的技术。Python库本文专注于Pytesseract、easyOCR、PyPDF2和LangChain库。实验数据是一个单页PDF文件,可在以下链接获取:h...
文字识别ocr中我们的需求是要识别 pdf 中的内容,包含文本,图片以及图片格式的表格哪个合适呢?
文字识别ocr中我们的需求是要识别 pdf 中的内容,包含文本,图片以及图片格式的表格,图片可能是横向的。哪个接口更合适呢?类似与这样的 pdf 文件。
pdf文件都是图片,视觉智能平台有api支持pdf文件转文本吗?
pdf文件都是图片,视觉智能平台有api支持pdf文件转文本吗?
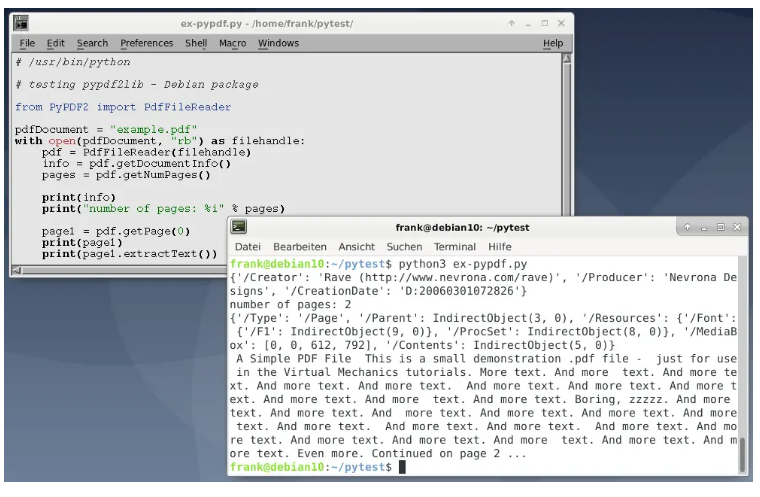
Python操作PDF-文本和图片提取(使用PyPDF2和PyMuPDF)
PDF文件格式如今,可移植文档格式(PDF)属于最常用的数据格式。在1990年,PDF文档的结构由Adobe定义。PDF格式的思想是,对于通信过程中涉及的双方(创建者,作者或发送者以及接收者)而言,传输的数据/文档看起来完全相同。工具和库适用于Python的PDF工具&#...

知识分享之Golang——读取pdf中纯文本内容
知识分享之Golang——读取pdf中纯文本内容背景知识分享之Golang篇是我在日常使用Golang时学习到的各种各样的知识的记录,将其整理出来以文章的形式分享给大家,来进行共同学习。欢迎大家进行持续关注。知识分享系列目前包含Java、Golang、Linux、Docker等等。开发环境系统:wi...
用iTextSharp读取PDF文档中文本内容:报错
用iTextSharp读取PDF文档中文本内容,执行这条Reader reader = new PdfReader(@"C:\WS.pdf");语句时,提示PDF header signature not found, using System; using System.Collections.G...
如何使用python中的PyMuPDF从PDF提取超链接上的文本?
问题来源于stackoverflow
C# 如何在PDF中绘制不同风格类型的文本
通过对控件Spire.PDF的测试,我们可以创建PDF文件并向文档中绘制文本、图片、表格、图形等内容,其中,对于绘制文本这一部分,Spire.PDF提供了三种字体类型来绘制文本,即: Standard fonts TrueType fonts Chinese, Japanese and Korean...
文本嵌入的经典模型与最新进展(下载PDF)
对通用嵌入的追求是一大趋势:在大型语料库上预训练好的嵌入,可以插入各种下游任务模型(情感分析、分类、翻译等),通过融合一些在更大的数据集中学习得到的常用词句表示,自动提高它们的性能。 这是一种迁移学习。最近,迁移学习被证明可以大幅度提高 NLP 模型在重要任务(如文本分类)上的性能。Jeremy H...
如何用Python批量提取PDF文本内容?
本文为你展示,如何用Python把许多PDF文件的文本内容批量提取出来,并且整理存储到数据框中,以便于后续的数据分析。 问题 最近,读者们在后台的留言,愈发五花八门了。 写了几篇关于自然语言处理的文章后,一种呼声渐强: 老师,pdf中的文本内容,有没有什么方便的方法提取出来呢? 我能体会到读者的心情...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐

社区圈子






