DataWorks请问这个该从什么方向去排查,我在EMR侧没有找到Spark相关的监控之类的?
DataWorks任务拉起的jar包中去获取SparkSession耗时达30+分钟,请问这个该从什么方向去排查,我在EMR侧没有找到Spark相关的监控之类的?
一天学完spark的Scala基础语法教程一、基础语法与变量(idea版本)-2创建测试类: 【day1/demo1.scala】 这里是有包名(后面有讲述)的
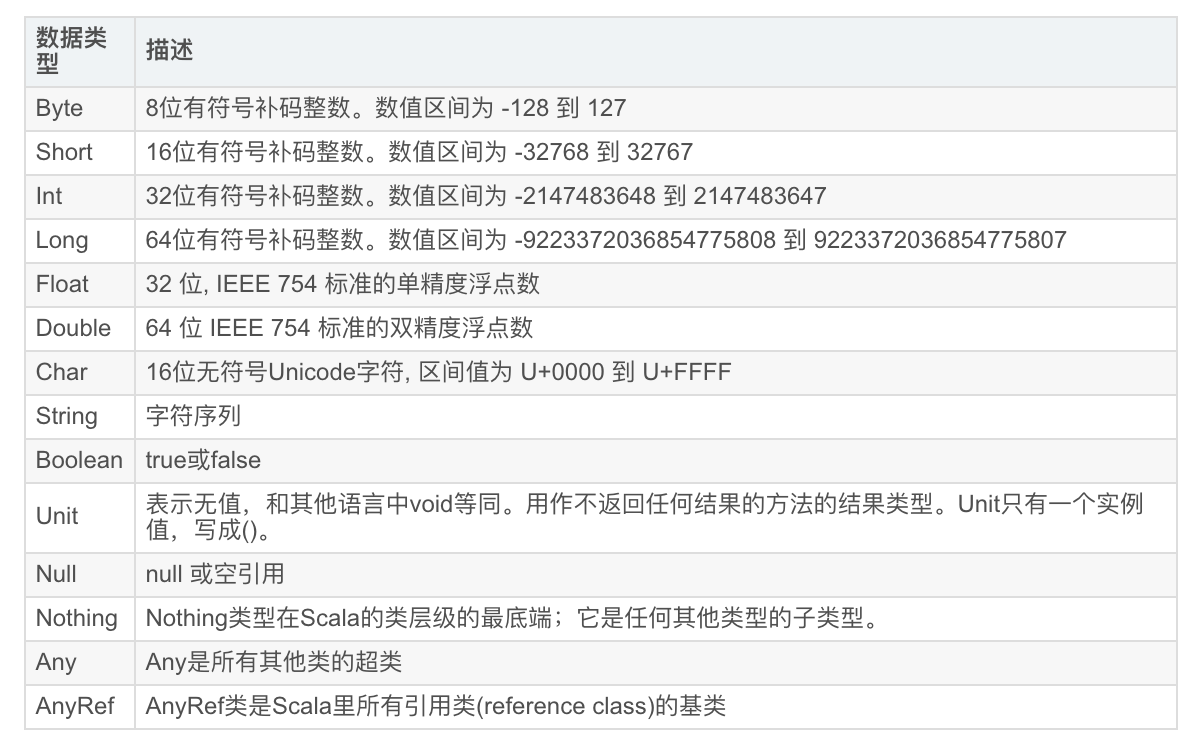
Scala 数据类型Scala 与 Java有着相同的数据类型,下表列出了 Scala 支持的数据类型:上表中列出的数据类型都是对象,也就是说scala没有java中的原生类型。在scala是可以对数字等基础类型调用方法的。Scala 基础字面量Scala 非常简单且直观。接下来我们会详细介绍 Sc...

spark hive类总是优先记载应用里面的jar包,跟spark.{driver/executor}.userClassPathFirst无关
背景最近在弄spark on k8s的时候,要集成同事的一些功能,其实这并没有什么,但是里面涉及到了hive的类问题(具体指这个org.apache.hadoop.hive.包下的类)。之后发现hive类总是优先加载应用jar包里的类,而忽略掉spark自带的系统jars包,这给我带了了很大的困扰&...
Spark的数据读取与保存之文件系统类数据读取与保存
Spark的数据读取及数据保存可以从两个维度来作区分:文件格式以及文件系统。文件格式分为:Text文件、Json文件、Csv文件、Sequence文件以及Object文件;文件系统分为:本地文件系统、HDFS、HBASE以及数据库。HDFSSpark的整个生态系统与Hadoop是完全兼容的,所以对于...
Spark的数据读取与保存之文件类数据读取与保存
Spark的数据读取及数据保存可以从两个维度来作区分:文件格式以及文件系统。文件格式分为:Text文件、Json文件、Csv文件、Sequence文件以及Object文件;文件系统分为:本地文件系统、HDFS、HBASE以及数据库。Text文件1)数据读取:textFile(String)scala...
Spark当中有哪些聚合类的算子,我们应该尽量避免什么类型的算子呢?
Spark当中有哪些聚合类的算子,我们应该尽量避免什么类型的算子呢?
spark算子可以分为多少类?
spark算子可以分为多少类?
Spark的用例分为哪些类?
Spark的用例分为哪些类?
基于Spark的机器学习实践 (八) - 分类算法
0 相关源码1 朴素贝叶斯算法及原理概述1.1 朴素贝叶斯简介◆ 朴素贝叶斯算法是基于贝叶斯定理和特征条件独立假设的一种分类方法◆ 朴素贝叶斯算法是一种基于联合概率分布的统计学习方法◆ 朴素贝叶斯算法实现简单,效果良好,是一种常用的机器学习方法1.2 贝叶斯定理◆ 朴素贝叶斯算法的一个基础是贝叶斯定...
Spark有哪些聚合类的算子,我们应该尽量避免什么类型的算子?
Spark有哪些聚合类的算子,我们应该尽量避免什么类型的算子?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark类相关内容
apache spark您可能感兴趣
- apache spark Hadoop
- apache spark数据
- apache spark分析
- apache spark Python
- apache spark可视化
- apache spark数据处理
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark SQL
- apache spark streaming
- apache spark Apache
- apache spark rdd
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark实战
- apache spark机器学习
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作