Spark Streaming实时流处理项目实战笔记——Kafka Consumer Java API编程
1、在控制台创建发送者kafka-console-producer.sh --broker-list hadoop2:9092 --topic zz >hello world2、消费者APIimport java.util.Arrays; import java.util.Properties...

Spark 原理 | 青训营笔记
Spark 原理 | 青训营笔记这是我参与「第四届青训营 」笔记创作活动的的第4天参考链接:1.第四届字节跳动青训营2.RDD介绍大数据处理引擎Spark介绍Spark生态组件:Spark Core:Spark核心组件,它实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等...

【Spark】【RDD】初次学习RDD 笔记 汇总 (2)
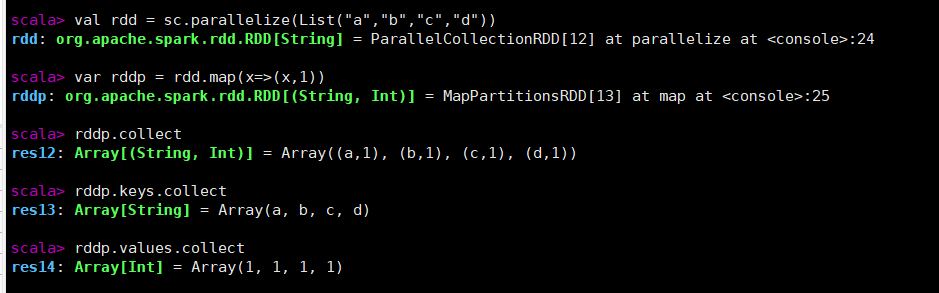
键值对RDDmapValuesval rdd = sc.parallelize(List("a","b","c","d")) //通过map创建键值对 var rddp = rdd.map(x=>(x,1)) rddp.collect rddp.keys.collect rddp.values...
【Spark】【RDD】初次学习RDD 笔记 汇总 (1)
RDDAuthor:萌狼蓝天【哔哩哔哩】萌狼蓝天【博客】https://mllt.cc【博客园】萌狼蓝天 - 博客园【微信公众号】mllt9920【学习交流QQ群】238948804目录RDD特点创建从内存中创建RDD从外部存储创建RDD1.创建本地文件2.启动spark-shell3.从本地文件系...
Spark快速入门(72集视频+源码+笔记)
Spark快速入门(72集视频+源码+笔记)1、什么是Spark?Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有...
Spark SQL 笔记
官方参考文档: http://spark.apache.org/docs/2.1.0/sql-programming-guide.html#creating-dataframes DataFrame A DataFrame is a Dataset organized into named colu...
Spark源码阅读笔记一——part of core
内部accumulator通过心跳报告给drivertask运行时可以累加accumulator,但是不能读取value,value只能在driver获取spark内部用一个weakhashmap保存accumulator,便于gc的清理 CacheManagerspark的类用于负责传递RDD的分...
Spark编程指南笔记
本文是参考Spark官方编程指南(Spark 版本为1.2)整理出来的学习笔记,主要是用于加深对 Spark 的理解,并记录一些知识点。 1. Spark介绍 Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce 框架,都是基于map reduce算法所实现的...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark笔记相关内容
apache spark您可能感兴趣
- apache spark大数据计算
- apache spark client
- apache spark报错
- apache spark模式
- apache spark任务
- apache spark Hive
- apache spark SQL
- apache spark yarn
- apache spark MaxCompute
- apache spark like
- apache spark streaming
- apache spark Apache
- apache spark数据
- apache spark Hadoop
- apache spark大数据
- apache spark rdd
- apache spark运行
- apache spark summit
- apache spark集群
- apache spark分析
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark flink
- apache spark Scala
- apache spark程序