
Spark SQL中的聚合与窗口函数
Spark SQL是Apache Spark的一个模块,用于处理结构化数据。在数据分析和处理中,聚合和窗口函数是非常重要的工具,它们可以对数据进行各种汇总、计算和分析。本文将深入探讨Spark SQL中的聚合与窗口函数,包括聚合函数、分组操作、窗口函数以及实际用例。 聚合函数 聚合函数是对数据集进行...
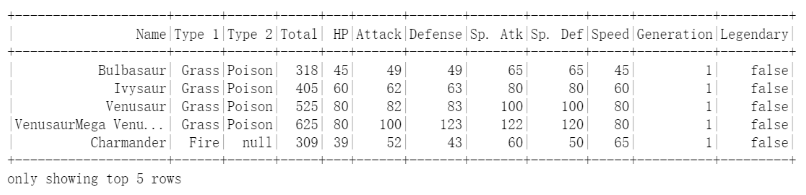
【Spark】(task2)PySpark数据统计和分组聚合
一、数据统计1.1 读取文件步骤1:读取文件https://cdn.coggle.club/Pokemon.csvimport pandas as pd from pyspark.sql import SparkSession # 创建spark应用 spark = SparkSession.bui...

Spark streaming / Flink 通过通道服务拿到实时数据变化,聚合,将统计结果写回到
Spark streaming / Flink 通过通道服务拿到实时数据变化,聚合,将统计结果写回到Tablestore 中sink 表中的架构图是什么样的?
Spark当中有哪些聚合类的算子,我们应该尽量避免什么类型的算子呢?
Spark当中有哪些聚合类的算子,我们应该尽量避免什么类型的算子呢?
spark中为什么要使用map-side预聚合的shuffle操作?
spark中为什么要使用map-side预聚合的shuffle操作?
如何在Spark中实现Count Distinct重聚合
背景 Count Distinct是SQL查询中经常使用的聚合统计方式,用于计算非重复结果的数目。由于需要去除重复结果,Count Distinct的计算通常非常耗时。 以如下查询为例,Count Distinct的实现方式主要有两种: SELECT region, COUNT(DISTINCT u...
Spark有哪些聚合类的算子,我们应该尽量避免什么类型的算子?
Spark有哪些聚合类的算子,我们应该尽量避免什么类型的算子?
海量监控日志基于EMR Spark Streaming SQL进行实时聚合
作者:伯箫,阿里云高级开发工程师。现在在阿里云表格存储团队,负责管控系统的开发,对NOSQL类数据库系统有一些了解。 前言 从EMR-3.21.0 版本开始将提供Spark Streaming SQL的预览版功能,支持使用SQL来开发流式分析作业。结果数据可以实时写入Tablestore。本文以Lo...
海量监控日志基于EMR Spark Streaming SQL进行实时聚合
前言 从EMR-3.21.0 版本开始将提供Spark Streaming SQL的预览版功能,支持使用SQL来开发流式分析作业。结果数据可以实时写入Tablestore。本文以LogHub为数据源,收集ECS上的日志数据,通过Spark Streaming SQL进行聚合后,将流计算结果数据实时写...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark大数据计算
- apache spark client
- apache spark报错
- apache spark模式
- apache spark任务
- apache spark Hive
- apache spark SQL
- apache spark yarn
- apache spark MaxCompute
- apache spark like
- apache spark streaming
- apache spark Apache
- apache spark数据
- apache spark Hadoop
- apache spark大数据
- apache spark rdd
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark分析
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark flink
- apache spark Scala
- apache spark程序