python爬虫的urllib库详解
1.什么是Urllibpython内置的HTTP请求库 urllib.request 请求模块 urllib.error 异常处理模块 urllib.parse url解析模块 urllib.ro...
urllib库中想要伪装爬虫的方法是什么?
urllib库中想要伪装爬虫的方法是什么?

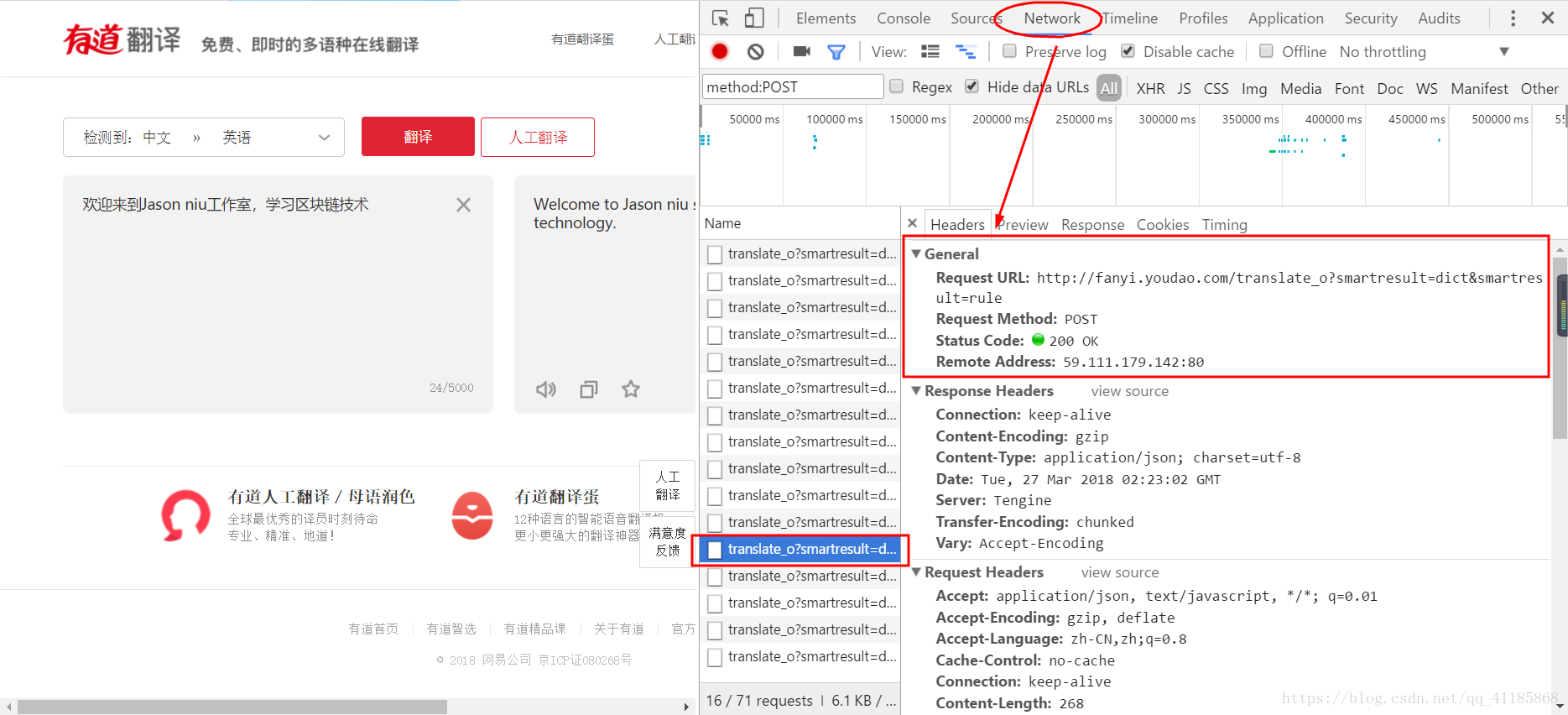
Crawler:基于urllib库+实现爬虫有道翻译
输出结果后期更新……设计思路第一步:首先要知道,data里面的内容是都需要在代码中发送给服务器的。第二步:理解反爬虫机制,找出加密参数。大多数网站的反爬虫的机制是对向服务器提交表单的动态值进行加密,所以,我们每翻译一次,就观察data里面有哪些参数是动态变化的。从这个网址来看,参数sa...

python爬虫urllib使用和进阶 | Python爬虫实战二
查看上一节:python爬虫分类和robots协议 python爬虫urllib使用和进阶 上节课已经介绍了爬虫的基本概念和基础内容,接下来就要开始内容的爬取了。 其实爬虫就是浏览器,只不过它是一个特殊的浏览器。爬取网页就是通过HTTP协议访问相应的网页,不过通过浏览器访问往往是人的行为,把这种行为...
爬虫的urllib库怎么使用
爬虫的urllib库怎么使用 问题来源于python学习网
15、web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块,然后将网页数据通过lxml下的etree转化为treedata的形式 urllib库中使用xpath表达式 etree.HTML()将获取到的html字符串,转换成树形结构,也就是xpath表达式可以获...
9、web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
封装模块 #!/usr/bin/env python # -*- coding: utf-8 -*- import urllib from urllib import request import j...
8、web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener()初始化IPinstall_opener()将代理IP设置成全局,当使用urlopen()请求时自动使用代理IP #!/usr/bin/env python # ...
7、web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执行下去 1.常见状态码 301:重定向到新的URL,永久性302:重定向到临时URL,非永久性304:请求的资源未更新400:非法请求401:请求未经授权403:禁止访问404:没找到对应页面500:服...
6、web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode("utf-8")将字节转化成字符串 #!/usr/bin/env python # -*- coding:utf-8 -*- import urllib.r...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子


最佳实践


