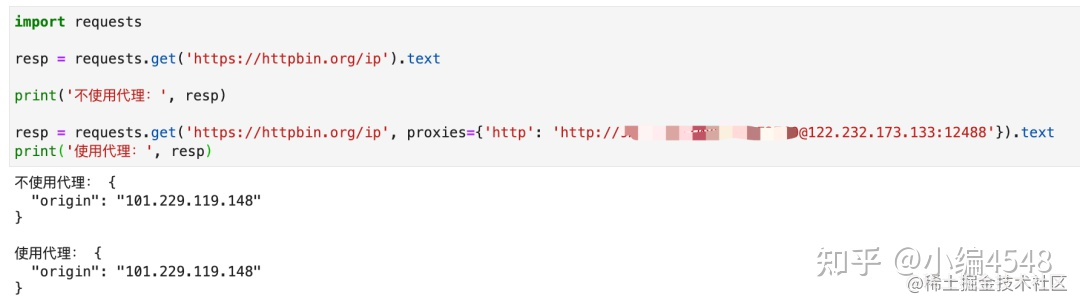
「Python」爬虫-10.代理与常见报错
开启掘金成长之旅!这是我参与「掘金日新计划 · 12 月更文挑战」的第1天,点击查看活动详情前言1.本文重点本文就关于爬虫代理以及在爬虫过程中可能出现的报错做一个汇总。如果,感兴趣的话,就继续往下看吧,不感兴趣的快run,开个玩笑2.参考链接为什么网站知道我的爬虫使用了代理? - 知乎 (zhihu...
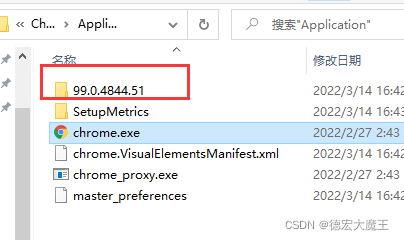
解决selenium可视化爬虫报错以及安装chromedriver系列踩坑问题
今天首次使用selenium爬虫,需要下载chrome浏览器,以及对应的驱动:1.下载chrome浏览器点我下载2.安装chromedriver驱动点我下载查看对应的版本方法:通过 桌面 ,属性,查看文件位置我的浏览器安装地址是C:\Program Files\Google\Chrome\Appli...

爬虫代码报错,U""怎么用呢?
for item in comment : print(eval('u"'+str(item)+'"')) print("----------") 第二行代码汇报所。我要怎样才能u解码item内容呢?求大神帮忙
python爬虫报错raise JSONDecodeError("Expecting value",
python爬虫报错raise JSONDecodeError("Expecting value", s, err.value),怎么处理?
cmd下执行scrapy爬虫程序,不报错也没有输出,求告知怎么回事 ?报错
cmd下执行scrapy爬虫程序,不报错也没有输出,求告知怎么回事 问题在这里,在开源中国写的,直接打开就行了。求告知怎么回事,万分感谢。 (https://www.oschina.net/question/3068158_2241004 "")
爬虫之scrapy报错spider 农田 ?报错
参照了此链接:https://www.cnblogs.com/derek1184405959/p/8450457.html 一模一样,但是一直报错 但是我的spider文件如下. tencentPosition.py中name为main文件: 想问下是什么问题
用爬虫抓网站源码的时候,把其中一段源码,保存到数据库的时候,就报错了。。?报错
这个怎么办啊?而且连接数据库的,我也设置了编码的,为utf-8
微博爬虫爬取不了内容,但也没报错?报错
#--coding:utf-8-- from future import unicode_literals import re import string import sys import os import urllib import urllib2 from bs4 import Beauti...
python scrapy 运行爬虫报错?报错
ubuntu14安装python,scrapy。项目运行报错,求大神指点。感谢。 Traceback (most recent call last): File "/usr/local/bin/scrapy", line 11, in sys.exit(ex...
scrapy 写的爬虫无输出也不报错,cmd下给的log如下,求告知怎么回事??报错
利用scrapy写的爬虫,在cmd下运行,没有输出,也不报错,请问是什么原因,是少安装包了吗?源码:https://github.com/876309067/secondDemo 如果你运行源码的话,请在pipelines里面修改一下文件输出路径,此代码是下载图片的。 cmd下log如下: 谁能帮我...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子


最佳实践


