
Flink,Storm,SparkStreaming性能对比
Yahoo 的 Storm 团队曾发表了一篇博客文章 ,并在其中展示了 Storm、Flink 和 Spark Streaming 的性能测试结果。该测试对于业界而言极 具价值,因为它是流处理领域的第一个基于真实应用程序的基准测试。该应用程序从 Kafka 消费广告曝光消息,从 Redis...

实时计算Flink版与开源 Apache Flink 性能对比
实时计算Flink版与开源 Apache Flink 性能对比实时计算Flink版产品是一套天然的云原生基础架构。在核心计算引擎上,相对于开源的Apache Flink 阿里云进行了多处核心功能的优化,这些优化也通过了阿里内部业务的锤炼。目前实时计算 Flink 产品,支持了阿里集团将近100个事业...

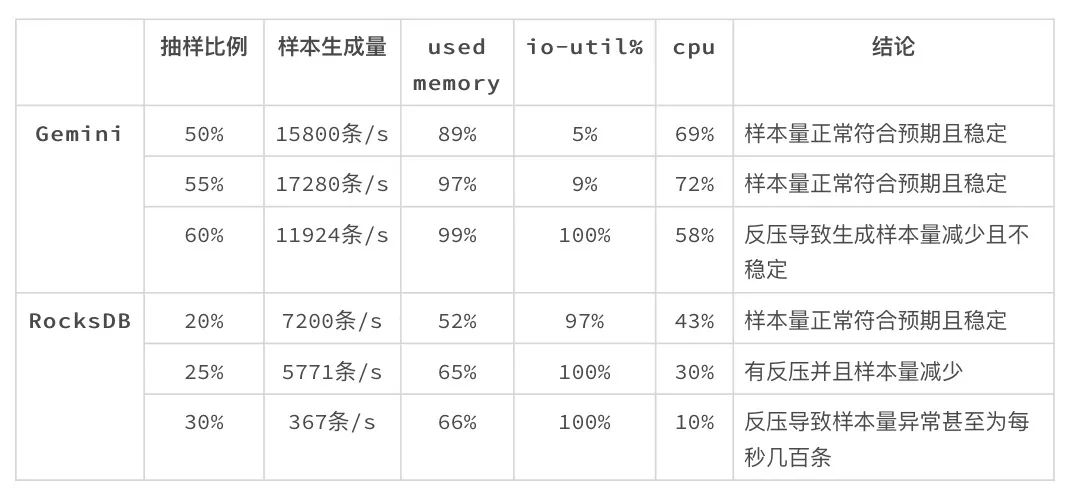
数据处理能力相差 2.4 倍?Flink 使用 RocksDB 和 Gemini 的性能对比实验
微博机器学习平台使用 Flink 实现多流 join 来生成在线机器学习需要的样本。时间窗口内的数据会被缓存到 state 里,且 state 访问的延迟通常决定了作业的性能。开源 Flink 的状态存储主要包括 RocksDB 和 Heap 两种,而在去年的 Flink Forward 大会上我们...
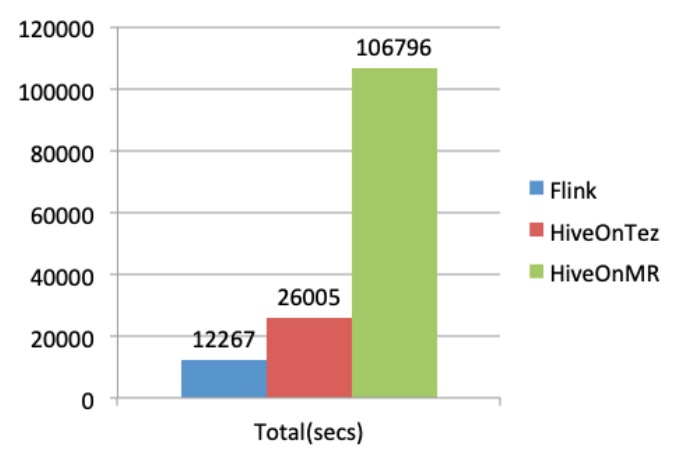
Flink 1.10 和 Hive 3.0 性能对比(附 Demo 演示 PPT)
作者:李劲松(之信) 如今的大数据批计算,随着 Hive 数仓的成熟,普遍的模式是 Hive metastore + 计算引擎。常见的计算引擎有 Hive on MapReduce、Hive on Tez、Hive on Spark、Spark integrate Hive、Presto integ...
流计算框架 Flink 与 Storm 的性能对比
(备注:原文链接https://mp.weixin.qq.com/s/b8Jiqj_SXM1acckTPyv57g) 作者:孙梦瑶 概述: 将分布式实时计算框架 Flink 与 Storm 进行性能对比,为实时计算平台和业务提供数据参考。 1. 背景 Apache Flink 和 Apache St...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子




最佳实践
更多




实时计算 Flink版您可能感兴趣
- 实时计算 Flink版json
- 实时计算 Flink版oracle
- 实时计算 Flink版数组
- 实时计算 Flink版临时文件
- 实时计算 Flink版配置参数
- 实时计算 Flink版堆内存
- 实时计算 Flink版捕获
- 实时计算 Flink版办法
- 实时计算 Flink版表
- 实时计算 Flink版pg
- 实时计算 Flink版CDC
- 实时计算 Flink版数据
- 实时计算 Flink版SQL
- 实时计算 Flink版mysql
- 实时计算 Flink版同步
- 实时计算 Flink版报错
- 实时计算 Flink版任务
- 实时计算 Flink版版本
- 实时计算 Flink版kafka
- 实时计算 Flink版Apache
- 实时计算 Flink版配置
- 实时计算 Flink版设置
- 实时计算 Flink版 CDC
- 实时计算 Flink版模式
- 实时计算 Flink版运行
- 实时计算 Flink版数据库
- 实时计算 Flink版Yarn
- 实时计算 Flink版checkpoint