
Hadoop【基础知识 01+02】【分布式文件系统HDFS设计原理+特点+存储原理】(部分图片来源于网络)【分布式计算框架MapReduce核心概念+编程模型+combiner&partitioner+词频统计案例解析与进阶+作业的生命周期】(图片来源于网络)
Hadoop是一个大数据解决方案。它提供了一套分布式系统基础架构。 核心内容包含 hdfs 和mapreduce。hadoop2.0 以后引入 yarn。hdfs 是提供数据存储的,mapreduce 是方便数据计算的。这篇主要说HDFS。 hdfs 对应 namenode 和 datanode...

Hadoop【基础知识 02】【分布式计算框架MapReduce核心概念+编程模型+combiner&partitioner+词频统计案例解析与进阶+作业的生命周期】(图片来源于网络)
1. 概述 同 HDFS 一样,Hadoop MapReduce 也采用了 Master/Slave(M/S)架构,具体如图所示。它主要由以下几个组件组成:Client、JobTracker、TaskTracker 和 Task。 下面分别对这几个组件进行介绍。 Client 我们将编写的 MapR...

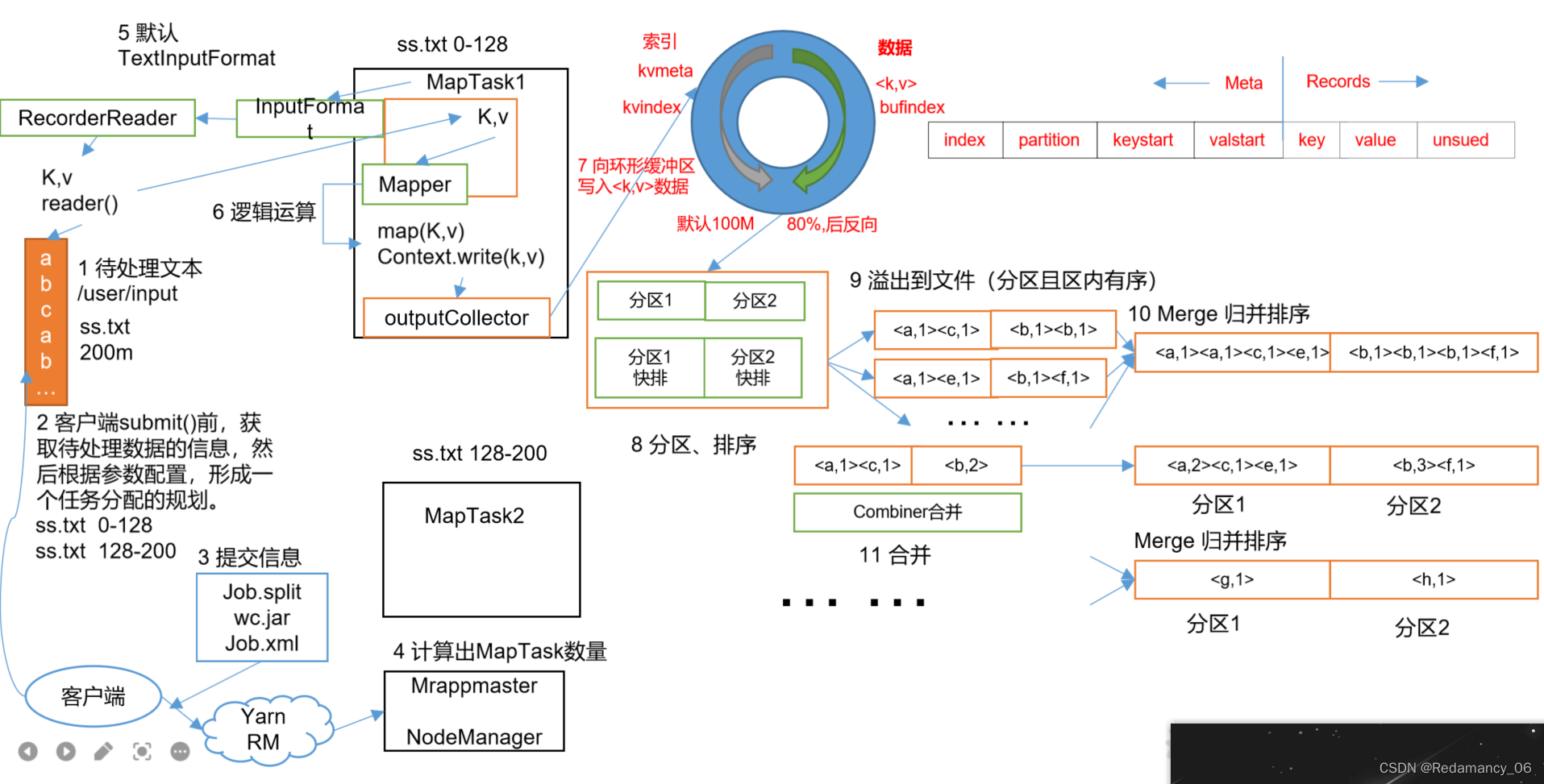
Hadoop中的MapReduce框架原理、Shuffle机制、Partition分区、自定义Partitioner步骤、在Job驱动中,设置自定义Partitioner、Partition 分区案例
13.MapReduce框架原理13.2MapReduce工作流程上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下:(1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中(2)从内存缓冲区不断溢...
hadoop中一个自定义的Partitioner需要实现什么功能?
hadoop中一个自定义的Partitioner需要实现什么功能?
Hadoop shuffle中mapreduce提供partitioner接口有什么作用?
Hadoop shuffle中mapreduce提供partitioner接口有什么作用?
Hadoop中Combiner和partitioner是用来干嘛的?
Hadoop中Combiner和partitioner是用来干嘛的?
Hadoop MapReduce工作详细流程(Partitioner/SortComparator/GroupingComparator)
转自:http://blog.sina.com.cn/s/blog_7581a4c30102veem.html map阶段 1. 使用job.setInputFormatClass(TextInputFormat)做为输入格式。注意输出应该符合自定义Map中定义的输出。 2. 进入Mapper的ma...
hadoop Partitioner 分区
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import org.apache.hadoop.io.Text; import org.apache.hadoop....
[Hadoop]MapReduce中的Partitioner与Combiner
Partitioners负责划分Maper输出的中间键值对的key,分配中间键值对到不同的Reducer。Maper输出的中间结果交给指定的Partitioner,确保中间结果分发到指定的Reduce任务。在每个Reducer中,键按排序顺序处理(Within each reducer, keys ...
[Hadoop]MapReduce中的Partitioner
partitioner在处理输入数据集时就像条件表达式(condition)一样工作。分区阶段发生在Map阶段之后,Reduce阶段之前。partitioner的个数等于reducer的个数(The number of partitioners is equal to the number of r...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








