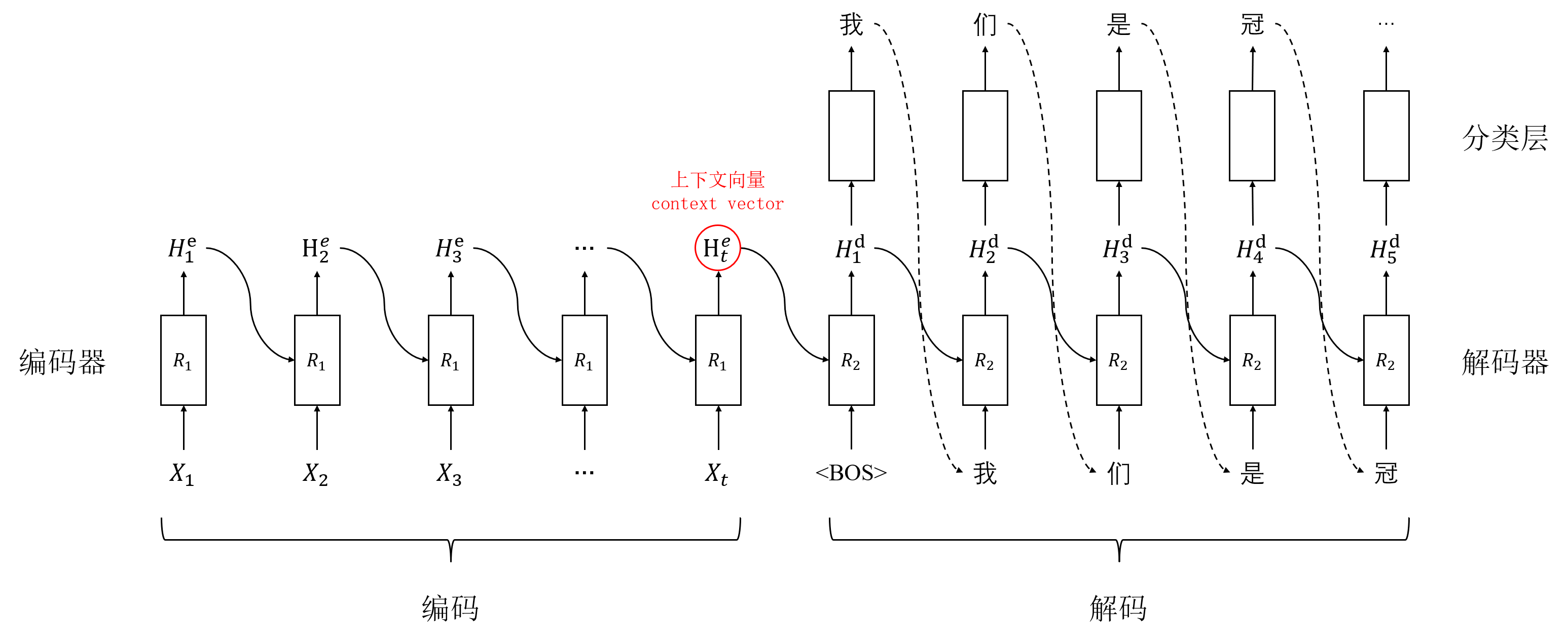
NLP学习笔记(五) 注意力机制
前言大家好,我是半虹,这篇文章来讲注意力机制 (Attention Mechanism) 在序列到序列模型中的应用正文在上一篇文章中,我们介绍了序列到序列模型,其工作流程可以概括为以下两个步骤首先,用编码器将输入序列编码成上下文向量,然后,用解码器将上下文向量解码成输出序列这里所说的上下文...

动手学深度学习(十四) NLP注意力机制和Seq2seq模型(下)
引入注意力机制的Seq2seq模型本节中将注意机制添加到sequence to sequence 模型中,以显式地使用权重聚合states。下图展示encoding 和decoding的模型结构,在时间步为t的时候。此刻attention layer保存着encodering看到的所有信息——即en...

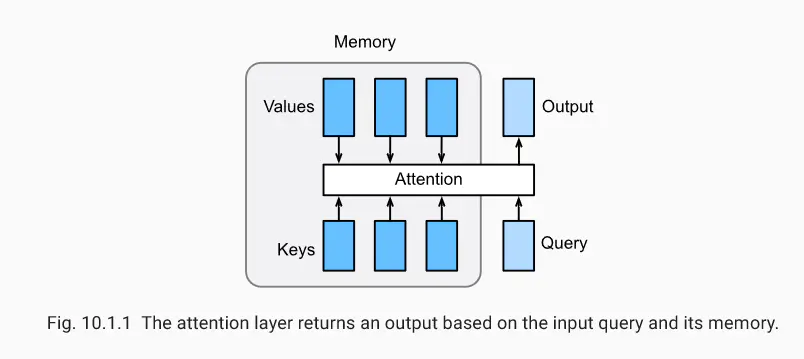
动手学深度学习(十四) NLP注意力机制和Seq2seq模型(上)
注意力机制在“编码器—解码器(seq2seq)”⼀节⾥,解码器在各个时间步依赖相同的背景变量(context vector)来获取输⼊序列信息。当编码器为循环神经⽹络时,背景变量来⾃它最终时间步的隐藏状态。将源序列输入信息以循环单位状态编码,然后将其传递给解码器以生成目标序列。然而这种结构存在着问题...

斯坦福NLP课程 | 第14讲 - Transformers自注意力与生成模型
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI教程地址:http://www.showmeai.tech/tutorials/36本文地址:http://www.showmeai.tech/article-detail/251声明:版权所有,转载请联系平台与作者并注...
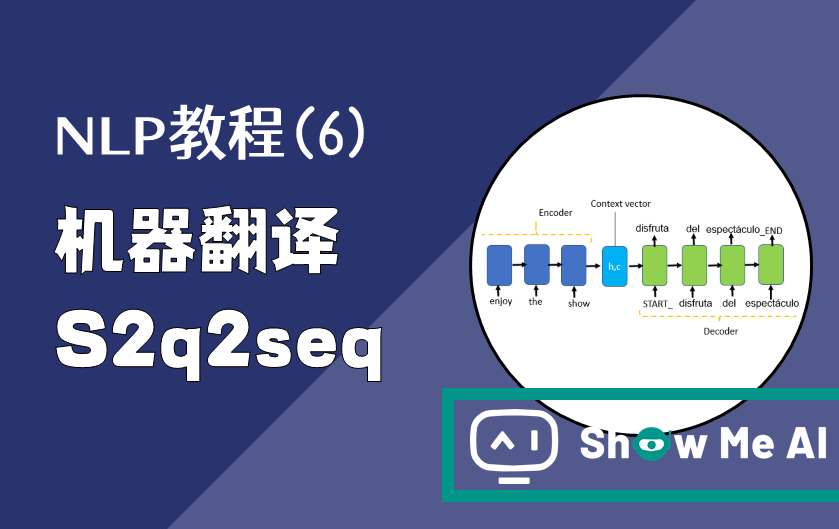
NLP教程(6) - 神经机器翻译、seq2seq与注意力机制
作者:韩信子@ShowMeAI教程地址:http://www.showmeai.tech/tutorials/36本文地址:http://www.showmeai.tech/article-detail/242声明:版权所有,转载请联系平台与作者并注明出处收藏ShowMeAI查看更多精彩内容本系列为...

谷歌NLP新模型「大鸟」突破BERT限制,稀疏注意力机制更省内存
谷歌最近又推出了一个重磅的稀疏注意力模型:Big Bird。 之前各种刷榜的BERT和它的各种衍生版本RoBERTa等,都是构建在Transformer基础上。 这些模型的核心竞争力就是全注意力机制,但这种机制会产生序列长度的二次依赖,如果输入的token过长,会撑爆内存,而长文...
深度 | 从各种注意力机制窥探深度学习在NLP中的神威
zenRRan: 希望这篇文章能帮助你了解各种注意力机制!从此不再迷茫!好啦,进入正题吧! 随着层级表征的兴起,自然语言处理在很多方面都应用了深度神经网络。它们可以实现语言建模、情感分析、机器翻译、语义解析等非常多的任务,这些序列建模任务可以使用循环神经网络、卷积神经网络甚至近来比较流行的 Tran...
解析广泛应用于NLP的自注意力机制(附论文、源码)
近年来,注意力(Attention)机制被广泛应用到基于深度学习的自然语言处理各个任务中,之前我对早期注意力机制进行过一些学习总结 [1]。 随着注意力机制的深入研究,各式各样的 Attention 被研究者们提出。在 2017年 6 月 Google 机器翻译团队在 arXiv 上放出的 Atte...
2017年ACL的四个NLP深度学习趋势 (二):可解释性和注意力(Interpretability and Attention)
更多深度文章,请关注:https://yq.aliyun.com/cloud 2017年ACL的四个NLP深度学习趋势 (一):语言结构和词汇嵌入(Linguistic Structure and Word Embeddings) 趋势3:可解释性(Interpretability) 我最近一直在思...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子




最佳实践




