请解释什么是 HTTP 请求头,以及在爬虫中为什么要设置请求头?
HTTP请求头(HTTP Request Headers)是HTTP请求的一部分,用于为服务器提供一些额外的信息。每个请求头都以名称开始,后面跟着一个冒号和一个空格,然后是值。这些值通常描述关于请求或请求主体的某些方面,如请求的来源、请求者的身份、请求的内容类型等。 在爬虫中设置请求头的原因主要有以...

Python爬虫:设置随机 User-Agent
Python爬虫:设置随机 User-Agent 在Python中编写爬虫时,为了模拟真实用户的行为并防止被服务器识别为爬虫,通常需要设置随机的User-Agent。你可以使用fake-useragent库来实现这一功能。首先,你需要安装fake-useragent库: ...

在Kotlin中设置User-Agent以模拟搜索引擎爬虫
前言随着双十一电商活动的临近,电商平台成为了狂欢的中心。对于商家和消费者来说,了解市场趋势和竞争对手的信息至关重要。在这个数字时代,爬虫技术成为了获取电商数据的有力工具之一。本文将以亚马逊为例,介绍如何使用Kotlin编写一个爬虫程序,通过设置User-Agent头部来模拟搜索引擎爬虫,从而成功抓取...
Python爬虫:Scrapy优化参数设置
修改 settings.py 文件# 增加并发 CONCURRENT_REQUESTS = 100 # 降低log级别 LOG_LEVEL = 'INFO' # 禁止cookies COOKIES_ENABLED = False # 禁止重试 RETRY_ENABLED = Fa...
Python爬虫:scrapy-splash的请求头和代理参数设置
3中方式任选一种即可1、lua中脚本设置代理和请求头:function main(splash, args) -- 设置代理 splash:on_request(function(request) request:set_proxy{ host = "27.0.0.1", p...
Python爬虫:scrapy爬虫设置随机访问时间间隔
代码示例random_delay_middleware.py# -*- coding:utf-8 -*- import logging import random import time class RandomDelayMiddleware(object): def __init__(self, ...
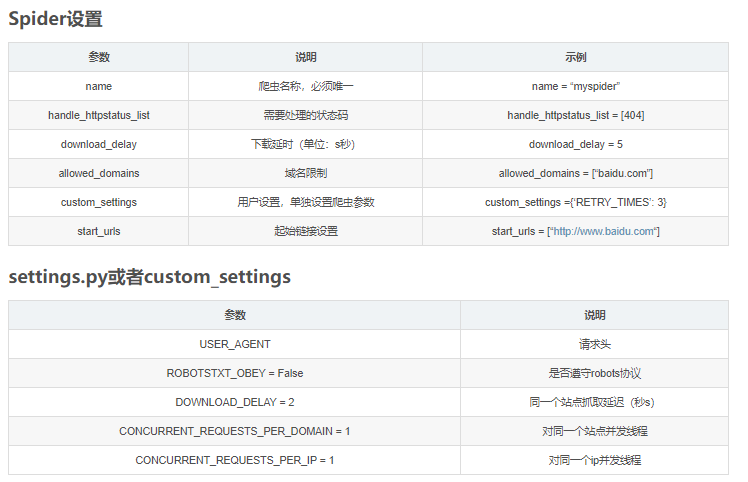
Python爬虫:scrapy框架Spider类参数设置
Python爬虫:scrapy框架Spider类参数设置
Python爬虫:scrapy框架log日志设置
Scrapy提供5层logging级别:1. CRITICAL - 严重错误 2. ERROR - 一般错误 3. WARNING - 警告信息 4. INFO - 一般信息 5. DEBUG - 调试信息logging设置通过在setting.py中进行以下设置可以被用来配置logging以下配置...
python爬虫设置请求头headers
使用python写爬虫的时候,通常要设置请求头。 以使用requests库访问百度为例,代码如下: import requests headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537...
Python爬虫:scrapy框架Spider类参数设置
Spider设置参数说明示例name爬虫名称,必须唯一name = “myspider”handle_httpstatus_list需要处理的状态码handle_httpstatus_list = [404]download_delay下载延时(单位:s秒)download_delay = 5all...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子


最佳实践


