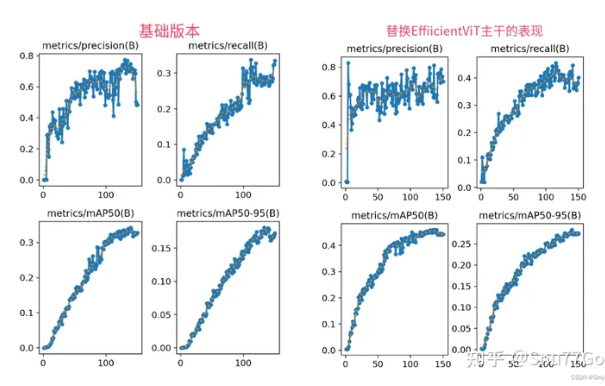
YOLOv5改进 | 2023主干篇 | EfficientViT替换Backbone(高效的视觉变换网络)
一、本文介绍 本文给大家带来的改进机制是EfficientViT(高效的视觉变换网络),EfficientViT的核心是一种轻量级的多尺度线性注意力模块,能够在只使用硬件高效操作的情况下实现全局感受野和多尺度学习。本文带来是2023年的最新版本的EfficientViT网络结构,论文题目是'Effi...

全新轻量化模型 | 轻量化沙漏网络助力视觉感知涨点
1、简介人体姿态估计(HPE)是计算机视觉中的一项经典任务,它主要通过识别人的关节的位置来表示人的方向。HPE可以用来理解和分析人类的几何和运动相关信息。Newell等人在Mask3D中提出的堆叠沙漏架构是第一个基于深度学习的HPE方法之一,因为经典方法在此之前主导了HPE文献。在这项工作中,利用重...


重塑自监督学习: DINO 网络如何颠覆视觉特征表示的常规方法
Title:Emerging Properties in Self-Supervised Vision TransformersPaper:https://openaccess.thecvf.com/content/ICCV2021/papers/Caron_Emerging_Properties_...
问下 视觉识别—通用分割,网络返回的图片轮廓很模糊,有办法弄清晰点吗?
问下 视觉识别—通用分割,网络返回的图片轮廓很模糊,有办法弄清晰点吗?

CVPR2021 | 视觉推理解释框架VRX:用结构化视觉概念作为解释网络推理逻辑的「语言」
大家好,我是Charmve。今天分享的一篇文章来自葛云皓,本文主要介绍了被 CVPR 2021 录用的文章《A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts》。本文提出...
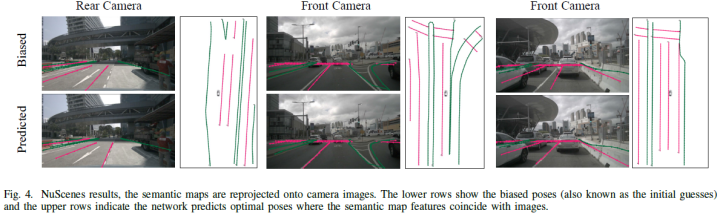
首篇!BEV-Locator:多目端到端视觉语义定位网络(清华&轻舟智航)(下)
实验和讨论nuScenes数据集结果NuScenes数据集包含城市地区的700个训练场景和150个测试场景,图像由6个环视摄像机拍摄。论文在nuScenes数据集上进行实验,以验证BEV定位器的有效性(用35个epoch训练)。论文从地图界面中提取地图元素。元素类型包括道路边界、车道分隔线和人行横道...
首篇!BEV-Locator:多目端到端视觉语义定位网络(清华&轻舟智航)(上)
摘要准确的定位能力是自动驾驶的基础。传统的视觉定位框架通过几何模型来解决语义地图匹配问题,几何模型依赖于复杂的参数调整,从而阻碍了大规模部署。本文提出了BEV定位器:一种使用多目相机图像的端到端视觉语义定位神经网络。具体地,视觉BEV(鸟瞰图)编码器提取多目图像并将其展平到BEV空间中。而语义地图特...

90+目标跟踪算法&九大benchmark!基于判别滤波器和孪生网络的视觉目标跟踪:综述与展望(下)
DCFS和Siamese跟踪器的明显开放问题DCF跟踪pipeline中的显著问题尽管具有重要的有前途特性,但标准DCF框架在应用于通用对象跟踪任务时面临着几个不同的挑战,包括特征表示、边界伪影和优化。下面我们确定并讨论了开发基于DCF的跟踪pipeline的这些重要挑战!1)特征表达在目标跟踪中,...
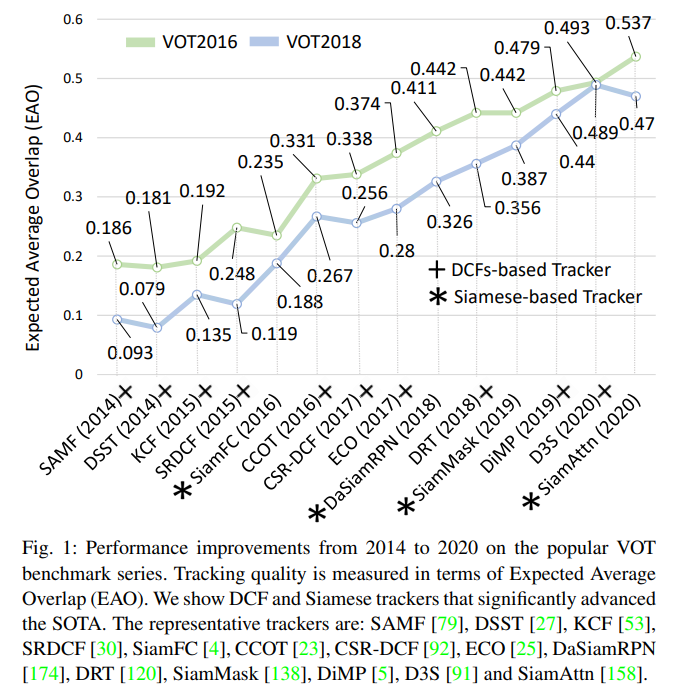
90+目标跟踪算法&九大benchmark!基于判别滤波器和孪生网络的视觉目标跟踪:综述与展望(上)
准确和鲁棒的视觉目标跟踪是最具挑战性和最基本的计算机视觉问题之一。它需要估计图像序列中目标的轨迹,仅考虑其初始位置和分割,或者以边界框的形式粗略近似。鉴别相关滤波器(DCF)和深度Siamese 网络(SNs)已经成为主要的跟踪范例,这促进了领域的重大发展。随着视觉目标跟踪在过去十年中的快速发展&a...
ViTGAN:用视觉Transformer训练生成性对抗网络 Training GANs with Vision Transformers
> @[TOC](目录)ViTGAN是加州大学圣迭戈分校与 Google Research提出的一种用视觉Transformer来训练GAN的模型。该论文已被NIPS(Conference and Workshop on Neural Information Processing System...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐

社区圈子




最佳实践




