[帮助文档] Filebeat采集Apache日志数据
当您需要查看并分析Apache日志数据时,可以使用Filebeat采集日志数据,并通过阿里云Logstash过滤采集后的日志数据,最终传输到Elasticsearch中进行分析。本文介绍如何通过Filebeat采集Apache日志数据。
[帮助文档] Apache Impala(CDH6)查询OSS数据_对象存储(OSS)
CDH是Cloudera提供的包含Apache Hadoop核心组件的企业级大数据发行版,已支持Hadoop 3.0.0。本文将详解如何配置CDH6环境下的Hadoop、Hive、Spark、Impala等组件,以实现对接阿里云OSS存储服务进行数据查询操作。

[帮助文档] ApacheSuperset如何连接Hologres并可视化分析数据
本文为您介绍Apache Superset如何连接Hologres并可视化分析数据。
[帮助文档] 接入ApacheSkyWalkingTrace数据到日志服务
本文介绍如何接入Apache SkyWalking Trace数据到日志服务,从而使用日志服务对Trace数据进行查询与分析。
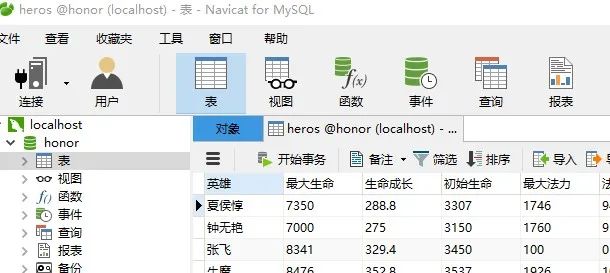
Apache Superset 1.2.0教程 (二)——快速入门(可视化王者英雄数据)
一、连接数据源首先确保mysql可以正常连接使用,并且准备好数据。登录进入superset,选择Databases点击右上方+号,新建数据库superset是通过SQLAlchemy连接数据库的。通过官方文档找到mysql的连接方式。https://docs.sqlalchemy.org/MySQL...
使用 Apache Superset 可视化 ClickHouse 数据
方法一:Python虚拟环境第一种方法直接在您的主机上安装 Superset。我们将首先创建一个 Python 虚拟环境。以下是常用命令。python3 -m venv clickhouse-sqlalchemy . clickhouse-sqlalchemy/bin/activate pip in...
[帮助文档] 如何在K8s环境下接入ApacheSkyWalkingTrace数据
本文介绍如何在阿里云K8s环境下将Apache SkyWalking Trace数据接入到日志服务中,实现Trace数据的存储、分析、可视化、告警和人工智能运维。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子







Apache您可能感兴趣
- Apache编译
- Apache库
- Apache下载
- Apache java
- Apache阻塞
- Apache tcp
- Apache dubbo
- Apache ip
- Apache服务器配置
- Apache flink
- Apache配置
- Apache rocketmq
- Apache安装
- Apache php
- Apache tomcat
- Apache服务器
- Apache linux
- Apache spark
- Apache开发
- Apache报错
- Apache服务
- Apache微服务
- Apache从入门到精通
- Apache hudi
- Apache doris
- Apache mysql
- Apache访问
- Apache日志