大数据技术与Python:结合Spark和Hadoop进行分布式计算
随着互联网的普及和技术的飞速发展,大数据已经成为当今社会的重要资源。大数据技术是指从海量数据中提取有价值信息的技术,它包括数据采集、存储、处理、分析和挖掘等多个环节。Python作为一种功能强大、简单易学的编程语言,在数据处理和分析领域具有广泛的应用。本文将介绍如何使用Python结合Spark和H...
「大数据」Hadoop生态系统:分布式计算系统
Apache IgniteApache Ignite In-Memory Data Fabric是一个分布式内存平台,用于实时计算和处理大规模数据集。它包括分布式键值内存存储,SQL功能,map-reduce和其他计算,分布式数据结构,连续查询,消息和事件子系统,Hadoop和Spark集成。 Ig...

flink hadoop 从0~1分布式计算与大数据项目实战(4)zookeeper内部原理流程简介以及java curator client操作集群注册,读取
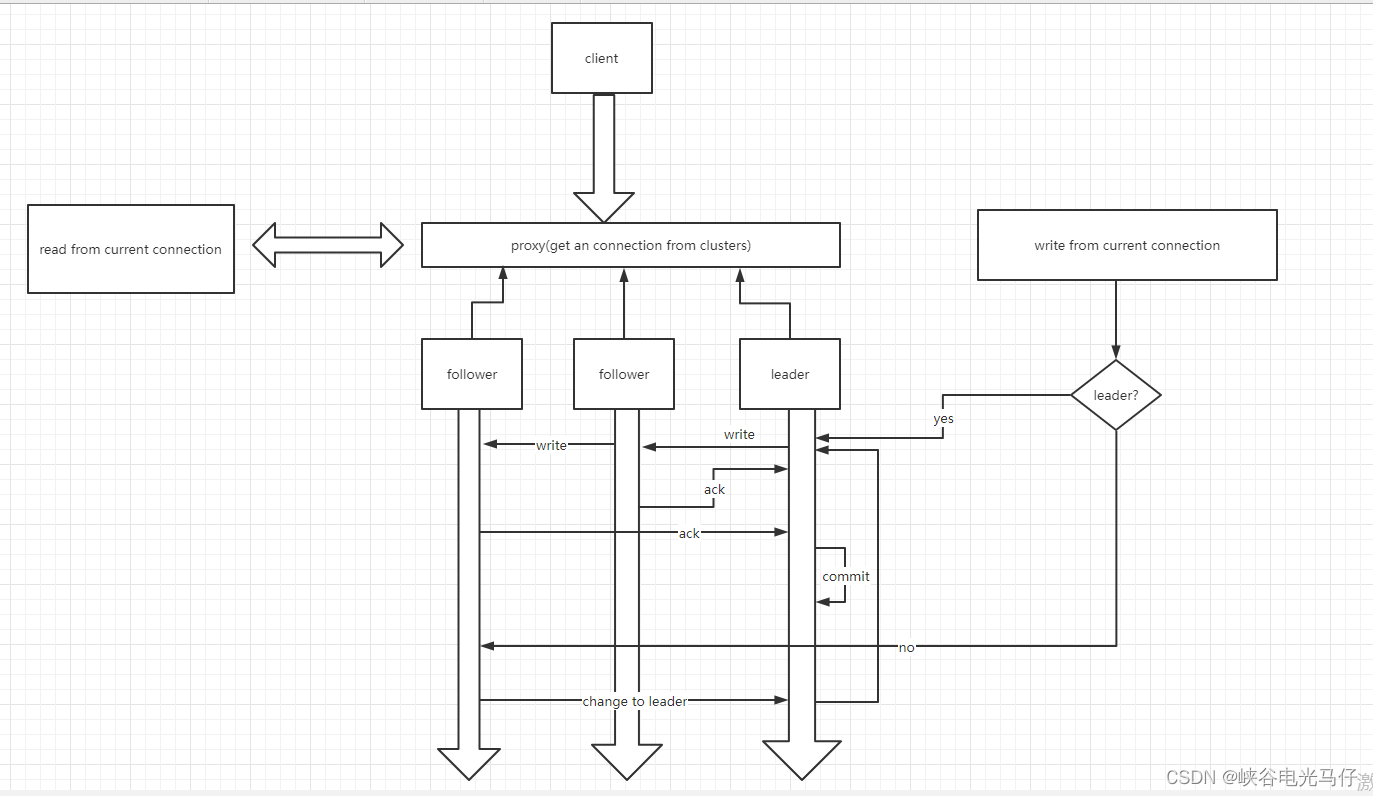
zookeeper内部原理流程用processon画的有点大,看不清的可以放大查看流程图详解1.zookeeper 集群(至少个节点)启动后,会自动选举出一个leader,其他节点为follower 跟随节点 2.client 连接给定的单地址或者集群,连接集群时,会挑选一个可用的节点进行连接,整个...
第3章 Hadoop分布式计算框架-MapReduce
第3章 Hadoop分布式计算框架-MapReduce一:判断题1:不同的Map任务之间不能互相通信T二:单选题1:MapReduce 框架提供了一种序列化键 /值对的方法 ,支持这种序列化的类能够在 Map 和 Reduce 过程中充当键或值 ,以下说法错误的是A.实现 Writable 接口的类...
【Hadoop】(三)资源管理器 YARN 和分布式计算框架 MapReduce
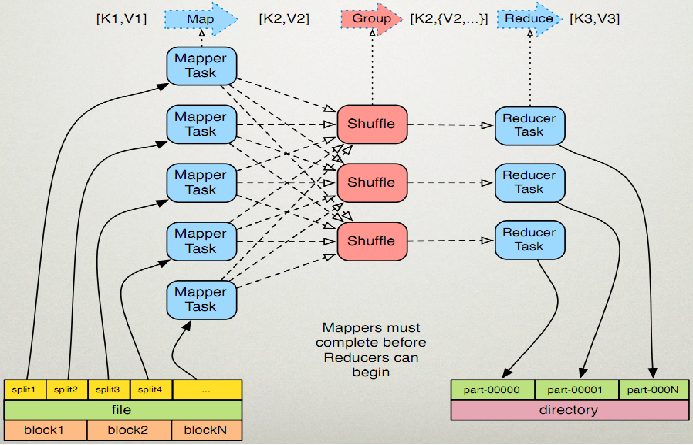
文章目录前言一 、MapReduce 介绍1. 基本介绍2. MR 数据流程方向3. MR 核心思想4. MR运行原理5. 块 、切片 、 map 、reduce 、组 、分区 、输出文件之间的关系6. 计算框架二、Hadoop 2.x-MapReduce1. Hadoop YARN2 .Hadoo...
在hadoop分布式计算框架中如何对全排序进行比较?
在hadoop分布式计算框架中如何对全排序进行比较?
在hadoop分布式计算框架中如何对全排序进行序列化?
在hadoop分布式计算框架中如何对全排序进行序列化?
在hadoop分布式计算框架中如何计算总流量?
在hadoop分布式计算框架中如何计算总流量?
在hadoop分布式计算框架中如何计算下行流量?
在hadoop分布式计算框架中如何计算下行流量?
hadoop中的在分布式计算框架中如何进行计算上行流量?
hadoop中的在分布式计算框架中如何进行计算上行流量?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








