SPARK push-based shuffle mapTask是怎么获取ESS列表信息
背景本文基于SPARK 3.2.1之前的文章SPARK SHUFFLE中 ShuffleId BlockManagerId 以及 与ESS(External Shuffle Server)交互,我们只是讲了一下大概的shuffle流程,这次来分析一下push-based shuffle,便于更好的理...
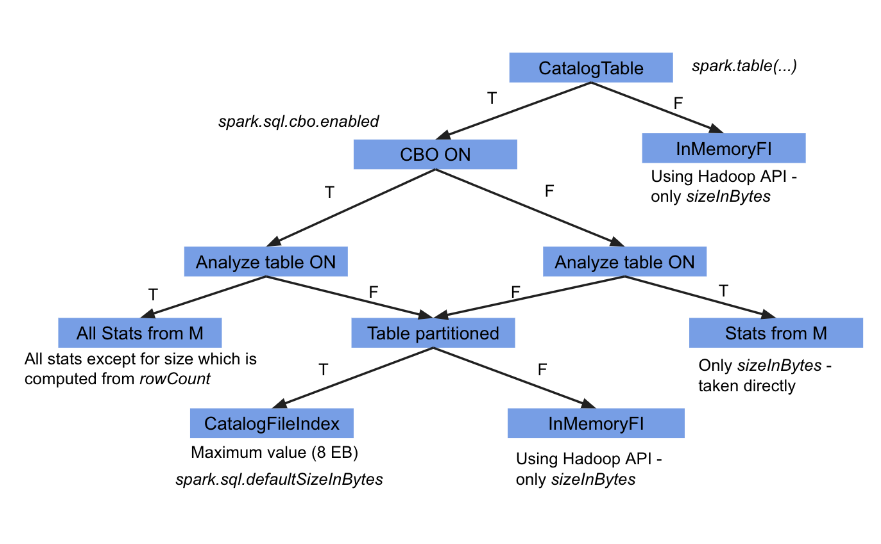
SPARK统计信息的来源-通过优化规则来分析
背景此文的分析基于spark 3.1.2且set spark.sql.catalogImplementation = hive 且表是分区的情况下在之前翻译的文章Spark SQL explaind中的统计信息-深入了解CBO优化里,我们说到,如果一个hive表是分区的,没有开启CBO,没有进行AT...

【spark系列10】spark logicalPlan Statistics (逻辑计划阶段的统计信息)
背景本文版本是spark 3.0.1分析逻辑阶段的统计信息,对于逻辑阶段的优化也是很重要的,比如broadcathashJoin,dynamic partitions pruning,本文分析一下spark 是怎么获取stastatics信息的直接到LogicalPlanStats:trait Lo...
MaxCompute Spark中Logview的主要信息作用是啥呢?
MaxCompute Spark中Logview的主要信息作用是啥呢?
Spark Parquet在行式存储下的统计信息是什么?
Spark Parquet在行式存储下的统计信息是什么?
[帮助文档] 调用ListSparkJob用于翻页提取某个数据湖分析Spark虚拟集群的历史作业详情信息
调用ListSparkJob用于翻页提取某个数据湖分析Spark虚拟集群的历史作业详情信息。
Spark批量加载文件集合,并从文件级别查找每个文件中的行以及其他信息
我有使用逗号分隔符指定的文件集合,如:hdfs://user/cloudera/date=2018-01-15,hdfs://user/cloudera/date=2018-01-16,hdfs://user/cloudera/date=2018-01-17,hdfs://user/cloudera...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark应用
- apache spark Python
- apache spark框架
- apache spark SQL
- apache spark运行
- apache spark MaxCompute
- apache spark serverless
- apache spark阿里云
- apache spark emr
- apache spark报错
- apache spark streaming
- apache spark Apache
- apache spark数据
- apache spark Hadoop
- apache spark大数据
- apache spark rdd
- apache spark summit
- apache spark集群
- apache spark模式
- apache spark分析
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark flink
- apache spark Scala
- apache spark任务
- apache spark程序