简单描述一下爬虫的工作原理。
爬虫的工作原理可以简单概括为以下几个步骤: 发送请求:爬虫程序会向目标网站发送 HTTP 请求,请求获取网页的内容。获取响应:目标网站接收到请求后,会返回相应的 HTTP 响应,其中包含了网页的源代码或其他数据。解析数据:爬虫程序会使用相应的库或工具,对返回的响应数据进行解析ÿ...

Python爬虫-代理池原理和搭建
代理池的维护 我们在上一节了解了利用代理可以解决目标网站封 IP 的问题。在网上有大量公开的免费代理,或者我们也可以购买付费的代理 IP,但是代理不论是免费的还是付费的,都不能保证都是可用的,因为可能此 IP 被其他人使用来爬取同样的目标站点而被封禁,或者代理服务器突然发生故障或网络繁忙。一旦我们选...

Python爬虫之Ajax数据爬取基本原理#6
前言 有时候我们在用 requests 抓取页面的时候,得到的结果可能和在浏览器中看到的不一样:在浏览器中可以看到正常显示的页面数据,但是使用 requests 得到的结果并没有。这是因为 requests 获取的都是原始的 HTML 文档,而浏览器中的页面则是经过 JavaScript 处理数据后...

Python爬虫的基本原理#2
我们可以把互联网比作一张大网,而爬虫(即网络爬虫)便是在网上爬行的蜘蛛。把网的节点比作一个个网页,爬虫爬到这就相当于访问了该页面,获取了其信息。可以把节点间的连线比作网页与网页之间的链接关系,这样蜘蛛通过一个节点后,可以顺着节点连线继续爬行到达下一个节点,即通过一个网页继续获取后续的网页,这样整个网...
Python爬虫之http基本原理#2
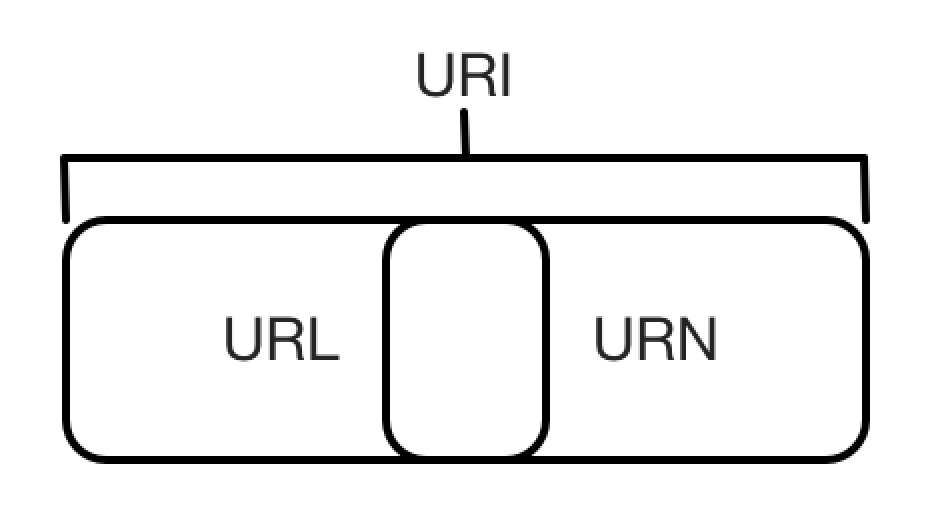
HTTP 基本原理 在本节中,我们会详细了解 HTTP 的基本原理,了解在浏览器中敲入 URL 到获取网页内容之间发生了什么。了解了这些内容,有助于我们进一步了解爬虫的基本原理。 1.URI 和 URL 这里我们先了解一下 URI 和 URL,URI 的全称为 Uniform Resource Id...
搜索引擎爬虫的工作原理是什么?底层原理是什么?
搜索引擎爬虫(Spider)是搜索引擎的重要组成部分,主要负责从互联网上抓取网页内容,并将其存储到搜索引擎的数据库中,以便后续的索引和检索。搜索引擎爬虫的工作原理通常包括以下几个步骤:确定抓取范围:爬虫程序首先需要确定需要抓取的网页范围,一般是从搜索引擎的数据库中获取待抓取的网页 URL。抓取网页内...
爬虫基本原理
爬虫概述爬虫就是获取页面来提取和保存信息的自动化程序。获取网页爬虫的工作首先是获取网页,这里就是获取网页的源代码。提取信息通过获取网页的源代码后来分析源代码并从中提取到我们想要使用的数据,首先最常用的方法是采用正则表达式,另外由于网页结构具有一定的规则,所以有些要根据CSS选择器或者XPath来提取...
Python爬虫:爬虫基本原理
爬虫:请求网站 并 提取数据 的 自动化程序爬虫基本流程:发起请求 -> 获取响应 -> 解析内容 -> 保存数据Request请求方式 Request Method:get post 请求url Request URL 请求头 Request Headers 请求体 Form D...
爬虫的基本原理是什么呢?
爬虫的基本原理是什么呢?
python爬虫的基本原理
python爬虫的基本原理学python很多人告诉你说,用python写个爬虫只需要一行代码,例如:import requestsres = requests.get("http://foofish.net")print(res.text)123数据就出来了,代码确实很精简,但是你知道背后的原理吗?...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子


最佳实践


