Python爬虫系列17-批量抓取某短视频平台某用户的全部作品
实战第一步:请求网络;获取到网站返回的数据内容 import requests cookies = { 'did': 'web_87ee5530f7dc26c5c05dfe66acf70e14', 'didv': '1649420428219', 'kpf': 'PC_WEB', 'kpn': 'K...
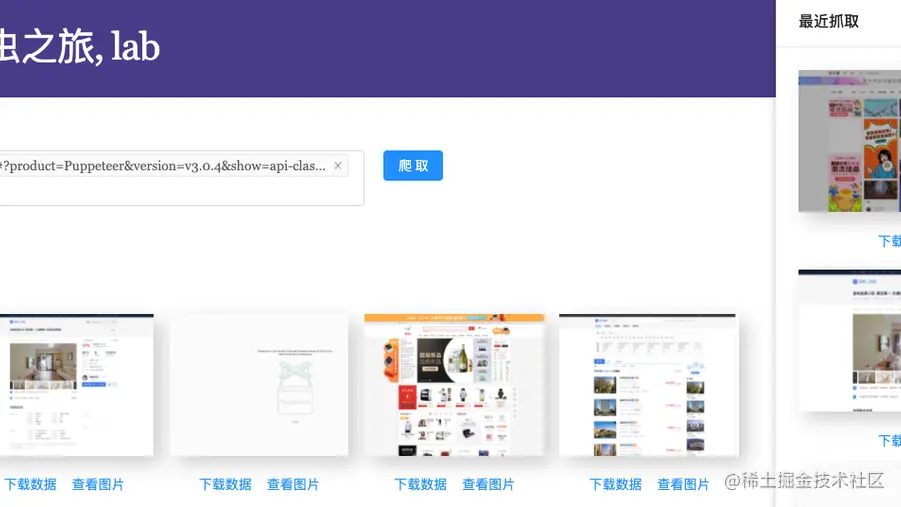
基于Apify+node+react/vue搭建一个有点意思的爬虫平台
前言熟悉我的朋友可能会知道,我一向是不写热点的。为什么不写呢?是因为我不关注热点吗?其实也不是。有些事件我还是很关注的,也确实有不少想法和观点。 但我一直奉行一个原则,就是:要做有生命力的内容。本文介绍的内容来自于笔者之前负责研发的爬虫管理平台, 专门抽象出了一个相对独立的功能模块为大家讲解如何使用...

百度站长平台提示“服务器错误:爬虫发起抓取,httpcode返回码是5xx ”,这种问题如何处理呢?
服务器错误:爬虫发起抓取,httpcode返回码是5XX,网站能正常访问,百度站长显示服务器错误,但服务器状态显示良好,这是哪里的问题该如何处理
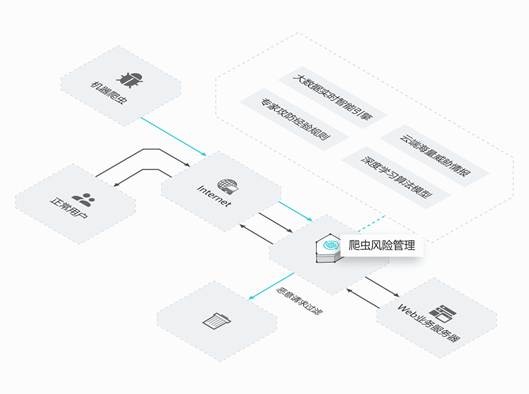
【云栖号案例 | 教育与科研机构】上学帮上云 阿里云助力教育资讯平台防爬虫
云栖号案例库:【点击查看更多上云案例】不知道怎么上云?看云栖号案例库,了解不同行业不同发展阶段的上云方案,助力你上云决策! 公司介绍 广州市藏星网络科技有限公司的主要产品是移动互联网应用“上学帮”,产品在各大应用市场以及微信公众号中均有上架。“上学帮”是国内领先的本地教育信息服务及交易平台,公司业务...
百度站长平台提示“服务器错误:爬虫发起抓取,httpcode返回码是5xx ”,这种问题如何处理呢?
百度站长平台链接异常提示“服务器错误:爬虫发起抓取,httpcode返回码是5xx ”,我的网站是是sxjzwl.cn这种问题如何处理呢?
爬虫进阶:Scrapy抓取科技平台Zealer
开篇 这次的目标网站也是本人一直以来有在关注的科技平台:Zealer,爬取的信息包括全部的科技资讯以及相应的评论。默认配置下运行,大概跑了半个多小时,最终抓取了5000+的资讯以及10几万的评论。 Zealer Media 说明及准备 开发环境:Scrapy、Redis、PostgreSQL...
如何租到靠谱的房子?Scrapy爬虫帮你一网打尽各平台租房信息!
又是一年n度的找房高峰期,各种租赁信息眼花缭乱,如何快速、高效的找到靠谱的房子呢? 不堪忍受各个租房网站缭乱的信息,一位技术咖小哥哥最近开发了一个基于 Scrapy 的爬虫项目,聚合了来自豆瓣,链家,58 同城等上百个城市的租房信息,统一集中搜索感兴趣的租房信息,还突破了部分网站鸡肋的搜索功能。 通...
天使轮获数百万投资,神箭手从爬虫切入构建大数据应用开发平台
随着数字化进程的加速,企业越来越重视数据的价值。根据IDC预计,全球大数据市场规模在2019年将达到1870亿美金。其中,企业除了关注自身的经营数据之外,对于外部数据,尤其是与自身息息相关的(如竞品动态、舆情信息等)数据也非常关注。 在获取这些数据时,最常用的手段就是爬虫技术。但传统的爬虫开发难度大...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子


最佳实践


