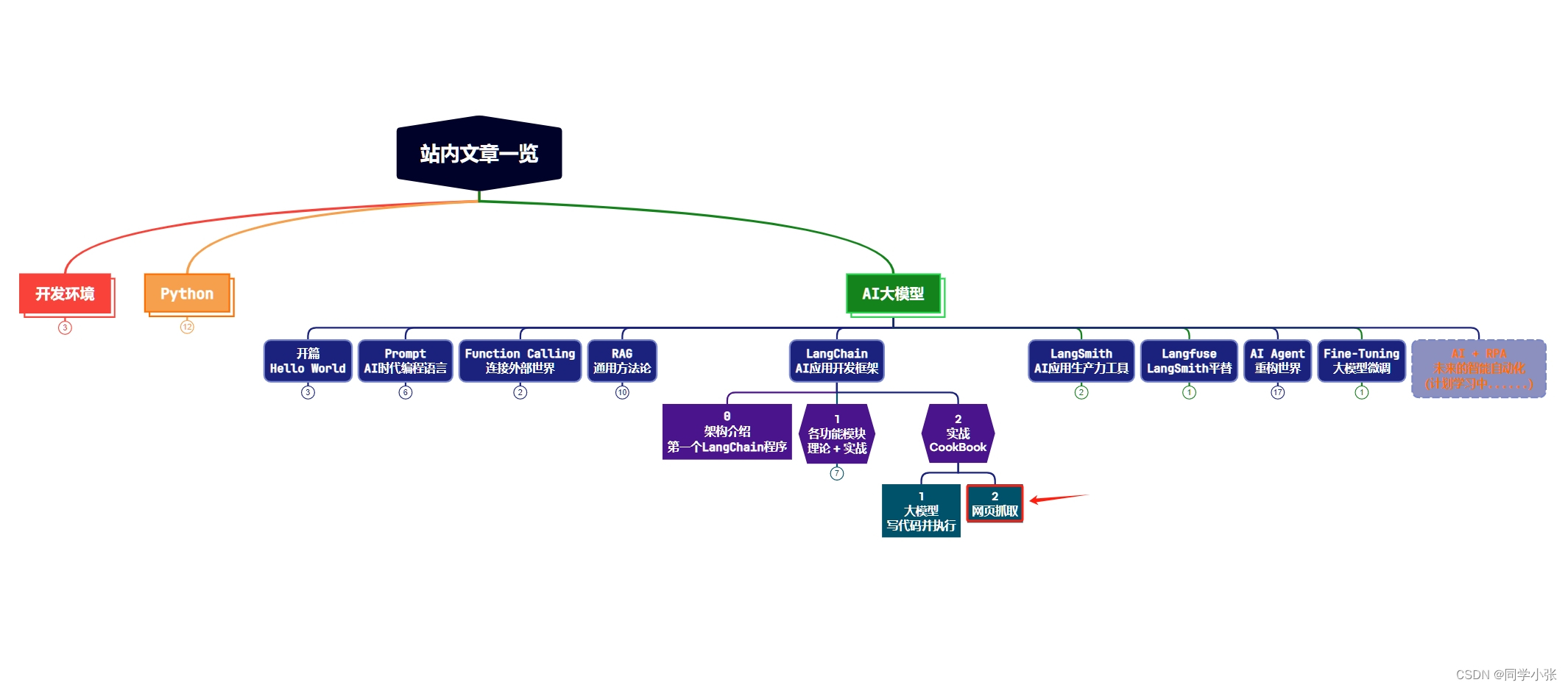
【AI大模型应用开发】【LangChain系列】实战案例2:通过URL加载网页内容 - LangChain对爬虫功能的封装
大家好,我是同学小张,日常分享AI知识和实战案例欢迎 点赞 + 关注 👏,持续学习,持续干货输出。+v: jasper_8017 一起交流💬,一起进步💪。微信公众号也可搜【同学小张】 🙏本站文章一览:Web检索是AI大模型应用的一个热...
爬虫识别-爬虫判断及封装 FlowScoreResult| 学习笔记
开发者学堂课程【大数据实战项目 - 反爬虫系统(Lua+Spark+Redis+Hadoop 框架搭建)第六阶段:爬虫识别-爬虫判断及封装 FlowScoreResult】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com/l...


爬虫识别-封装数据成 processedData|学习笔记
开发者学堂课程【大数据实战项目:反爬虫系统(Lua+Spark+Redis+Hadoop 框架搭建)第五阶段:爬虫识别-封装数据成 processedData】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com/l...
爬虫识别-main 方法及封装 processData 总结|学习笔记
开发者学堂课程【大数据实战项目:反爬虫系统(Lua+Spark+Redis+Hadoop 框架搭建)第五阶段:爬虫识别-main 方法及封装 processData 总结】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun...
Python爬虫:对selenium的webdriver进行简单封装
在使用selenium过程中,发现经常需要使用的两个参数user-agent请求头 和 proxy代理,设置需要一大堆代码requests就比较简单,于是乎 Browser类 就被封装成了类似requests库的一个模块,便于平时爬虫使用项目说明: PHANTOMJS 和 Chrome 浏览器,获取...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子


最佳实践


