【大数据技术Hadoop+Spark】Flume、Kafka的简介及安装(图文解释 超详细)
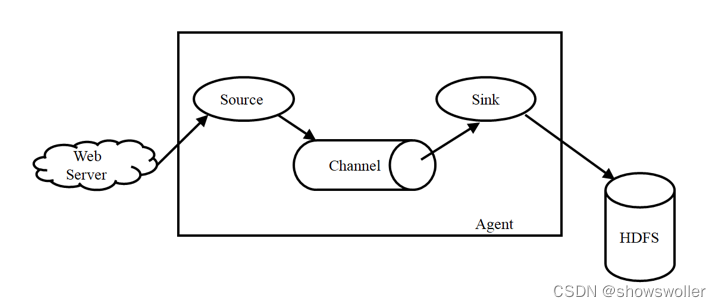
Flume简介Flume是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Flume主要由3个重要的组件构成:1)Source:...
Hadoop学习笔记(HDP)-Part.19 安装Kafka
目录Part.01 关于HDPPart.02 核心组件原理Part.03 资源规划Part.04 基础环境配置Part.05 Yum源配置Part.06 安装OracleJDKPart.07 安装MySQLPart.08 部署Ambari集群Part.09 安装OpenLDAPPart.10 创建集...

Hadoop生态系统中的实时数据处理技术:Apache Kafka和Apache Storm的应用
Hadoop生态系统是一个开源的分布式计算和存储平台,它提供了各种工具和技术来处理大规模数据集。其中,实时数据处理是一个重要的应用场景,它可以帮助企业实时地处理和分析海量数据,以及快速做出决策。在Hadoop生态系统中,Apache Kafka和Apache Storm是两个常用的实时数据处理技术。...

如何查看spark与hadoop、kafka、Scala、flume、hive等兼容版本【适用于任何版本】
方法当我们安装spark的时候,很多时候都会遇到这个问题,如何找到对应spark的各个组件的版本,找到比较标准的版本兼容信息。答案在spark源码中的pom文件。首先我们从官网下载源码。进入官网http://spark.apache.org选择download,然后我们看到下面内容# Master ...

解决问题:在格式化Hadoop之后无法使用HBase和Kafka
抛出问题:在初学Hadoop的时候,由于自己手残,把Hadoop格式化了,结果导致很多数据丢失,hbase和kafka不能正常使用,如图所示:查找问题:于是我将hbase全部重新安装,结果还是不能解决。后来经过高人指点,找出了出现这种问题的原因:...
如果想搭建一套分布式的训练集群,除了kafka、TensorFlow、hadoop、flink、zo
如果想搭建一套分布式的训练集群,除了kafka、TensorFlow、hadoop、flink、zookeeper,还需要搭建什么吗? 本问题来自阿里云开发者社区的【11大垂直技术领域开发者社群】。 点击这里欢迎加入感兴趣的技术领域群。
[@徐雷frank][¥20]如何将kafka中的数据快速导入Hadoop?
kafka的另一个有效用途是将数据导入Hadoop。具体该如何导入呢?
Hadoop完全分布式安装Kafka
应用场景 按照搭建hadoop完全分布式集群博文搭建完hadoop集群后,发现hadoop完全分布式集群自带了HDFS,MapReduce,Yarn等基本的服务,一些其他的服务组件需要自己重新安装,比如Hive,Hbase,sqoop,zookeeper,spark等,这些组件集群模式都在前面相关博...
Kafka在行动:7步实现从RDBMS到Hadoop的实时流传输
对于寻找方法快速吸收数据到Hadoop数据池的企业, Kafka是一个伟大的选择。Kafka是什么? 它是一个分布式,可扩展的可靠消息系统,把采取发布-订阅模型的应用程序/数据流融为一体。 这是Hadoop的技术堆栈中的关键部分,支持实时数据分析或物联网数据货币化。 本文目标读者是技术人员。 继续读...
Kafka实战:从RDBMS到Hadoop,七步实现实时传输
本文是关于Flume成功应用Kafka的研究案例,深入剖析它是如何将RDBMS实时数据流导入到HDFS的Hive表中。 对于那些想要把数据快速摄取到Hadoop中的企业来讲,Kafka是一个很好的选择。Kafka是什么?Kafka是一个分布式、可伸缩、可信赖的消息传递系统,利用发布-订阅模型来集成应...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








