大数据技术与Python:结合Spark和Hadoop进行分布式计算
随着互联网的普及和技术的飞速发展,大数据已经成为当今社会的重要资源。大数据技术是指从海量数据中提取有价值信息的技术,它包括数据采集、存储、处理、分析和挖掘等多个环节。Python作为一种功能强大、简单易学的编程语言,在数据处理和分析领域具有广泛的应用。本文将介绍如何使用Python结合Spark和H...
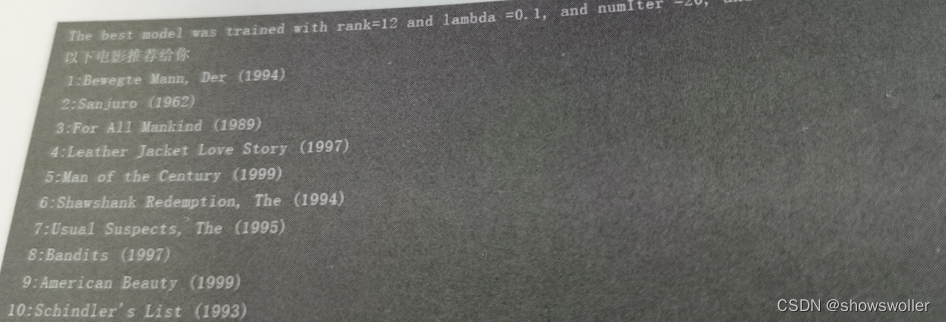
【大数据技术】Spark MLlib机器学习协同过滤电影推荐实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~协同过滤————电影推荐协同过滤是利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度。在协同过滤算法中有着两个分支,分别是基于群体用户的协同过滤(UserCF)和基于物品的协同过滤(ItemCF)。在电影推荐系统中,通常分为针对用户推荐电...


【大数据技术】Spark MLlib机器学习线性回归、逻辑回归预测胃癌是否转移实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~线性回归过工具类MLUtils加载LIBSVM格式样本文件,每一行的第一个是真实值y,有10个特征值x,用1:double,2:double分别标注,即建立需求函数:y=a_1x_1+a_2x_2+a_3x_3+a_4x_4+…+a_10x_10通...
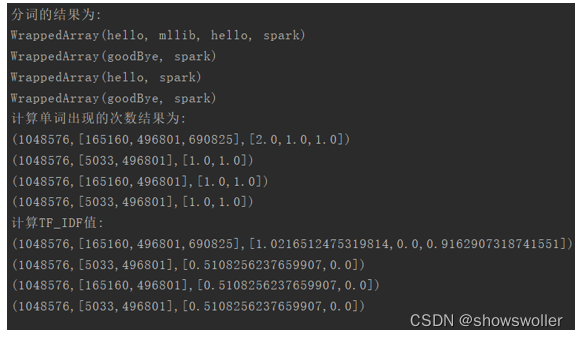
【大数据技术】Spark MLlib机器学习特征抽取 TF-IDF统计词频实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~特征抽取 TF-IDFTF-IDF是两个统计量的乘积,即词频(Term Frequency, TF)和逆向文档频率(Inverse Document Frequency, IDF)。它们各自有不同的计算方法。TF是一个文档(去除停用词之后)中某个词...
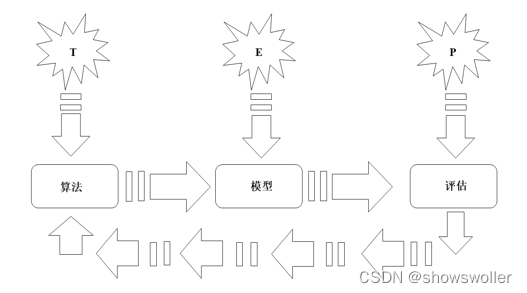
【大数据技术】Spark MLlib机器学习库、数据类型详解(图文解释)
机器学习的定义机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。机器学习的构建过程是利用数据通过算法构建出模型并对模型进行评估,评估的性能如果达到要求就拿这个模型来测试其他的数据,如果达不到要求就要调整算法来重新建立模型,再次进行评估,如此循环往复,最终获得满意的经验来处理其他的数...

【大数据技术】Spark+Flume+Kafka实现商品实时交易数据统计分析实战(附源码)
需要源码请点赞关注收藏后评论区留言私信~~~Flume、Kafka区别和侧重点1)Kafka 是一个非常通用的系统,你可以有许多生产者和消费者共享多个主题Topics。相比之下,Flume是一个专用工具被设计为旨在往HDFS,HBase等发送数据。它对HDFS有特殊的优化,并且集成了Hadoop的安...
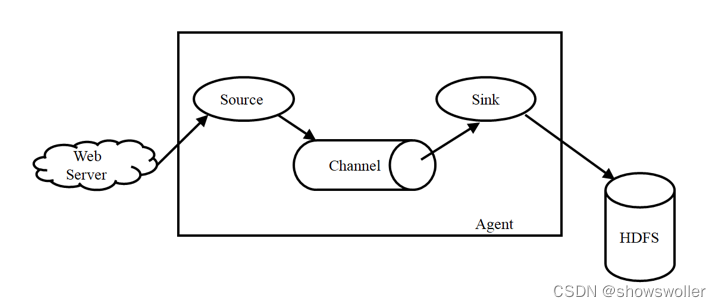
【大数据技术Hadoop+Spark】Flume、Kafka的简介及安装(图文解释 超详细)
Flume简介Flume是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Flume主要由3个重要的组件构成:1)Source:...

【大数据技术Spark】DStream编程操作讲解实战(图文解释 附源码)
DStream编程批处理引擎Spark Core把输入的数据按照一定的时间片(如1s)分成一段一段的数据,每一段数据都会转换成RDD输入到Spark Core中,然后将DStream操作转换为RDD算子的相关操作,即转换操作、窗口操作以及输出操作。RDD算子操作产生的中间结果数据会保存在内存中,也可...
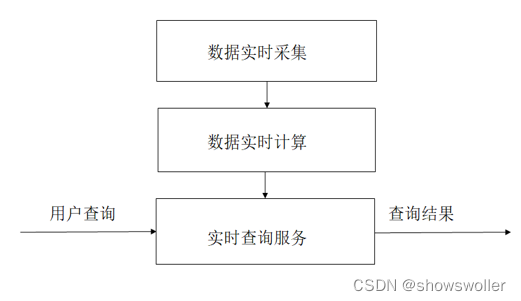
【大数据技术】流数据、流计算、Spark Streaming、DStream的讲解(图文解释 超详细)
流数据和流计算在大数据时代,数据可以分为静态数据和流数据,静态数据是指在很长一段时间内不会变化,一般不随运行而变化的数据。流数据是一组顺序、大量、快速、连续到达的数据序列,一般情况下数据流可被视为一个随时间延续而无限增长的动态数据集合。应用于网络监控、传感器网络、航空航天、气象测控和金融服务等领域但...
【大数据技术Spark】Spark SQL操作Dataframe、读写MySQL、Hive数据库实战(附源码)
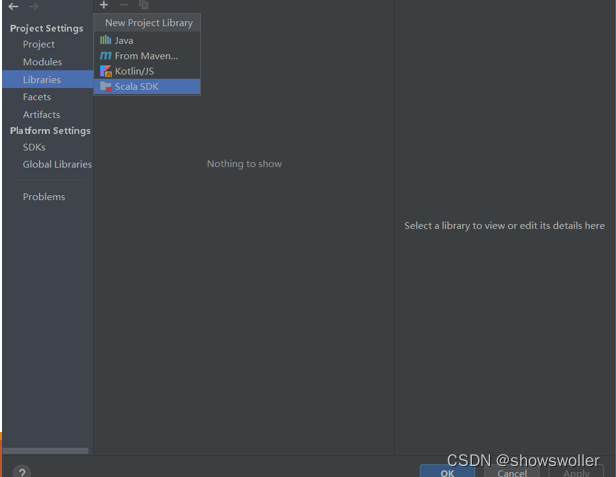
需要源码和依赖请点赞关注收藏后评论区留言私信~~~一、Dataframe操作步骤如下1)利用IntelliJ IDEA新建一个maven工程,界面如下2)修改pom.XML添加相关依赖包3)在工程名处点右键,选择Open Module Settings4)配置Scala Sdk,界面如下5)新建文件...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark Hadoop
- apache spark数据
- apache spark分析
- apache spark Python
- apache spark可视化
- apache spark数据处理
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark SQL
- apache spark streaming
- apache spark Apache
- apache spark rdd
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作