
【Python数据挖掘】数据可视化及数据对象的相似性度量算法详解(超详细 附源码)
需要PPT和源码请点赞关注收藏后评论区留言私信~~~一、数据可视化数据可视化(Data Visualization)通过图形清晰有效地表达数据。它将数据所包含的信息的综合体,包括属性和变量,抽象化为一些图表形式。数据可视化方法包括:基于像素的技术几何投影技术基于图符的技术和基于图形的技术几何投影技术...
文本挖掘与数据挖掘在研究对象和对象结构相比有什么不同呢?
文本挖掘与数据挖掘在研究对象和对象结构相比有什么不同呢?

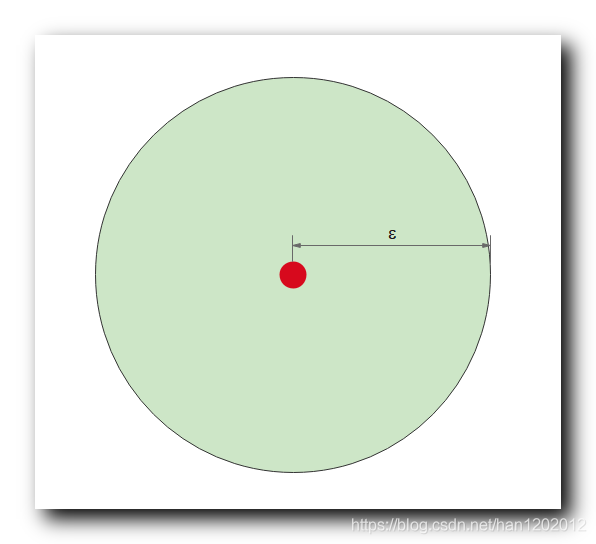
【数据挖掘】基于密度的聚类方法 - DBSCAN 方法 ( K-Means 方法缺陷 | 基于密度聚类原理及概念 | ε-邻域 | 核心对象 | 直接密度可达 | 密度可达 | 密度连接 )(三)
IX . 密度可达1 . 密度可达 : p pp 密度可达 q qq , 存在一个 由 核心对象 组成的链 , p pp 直接密度可达 p 1 p_1p 1 , p 1 p_1p 1 直接密度可达 p 2 p_2p 2 , ⋯ \cdots⋯ , p n − 1 ...
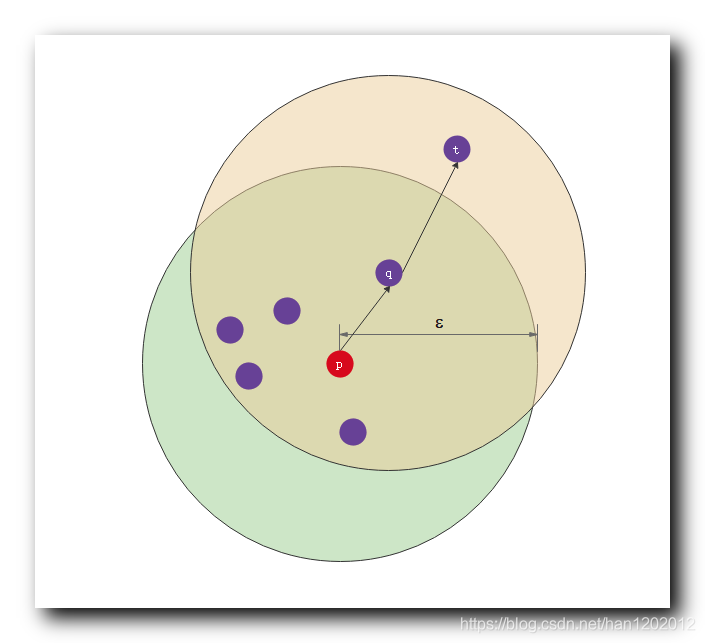
【数据挖掘】基于密度的聚类方法 - DBSCAN 方法 ( K-Means 方法缺陷 | 基于密度聚类原理及概念 | ε-邻域 | 核心对象 | 直接密度可达 | 密度可达 | 密度连接 )(二)
IV . 基于密度的聚类方法1 . 基于密度的聚类方法 :① 方法迭代原理 : 相邻区域的密度 , 即 单位空间内 数据样本 点的个数 , 超过用户定义的某个阈值 , 那么该区域需要进行聚类 , 如果低于某个阈值 , 聚类停止 , 算法终止 ;② 聚类分组前提 : 如果想要将多个 数据样本 划分到一...

【数据挖掘】基于密度的聚类方法 - DBSCAN 方法 ( K-Means 方法缺陷 | 基于密度聚类原理及概念 | ε-邻域 | 核心对象 | 直接密度可达 | 密度可达 | 密度连接 )(一)
I . K-Means 算法在实际应用中的缺陷1 . K-Means 算法中中心点选择是随机的 : 随机地选择聚类分组的中心点 ;① 选择实点 : 可以选择实点 ( 当前现有的样本值 ) 作为聚类中心点 ;② 生成虚点 : 也可以选择生成虚点 ( 任意位置模拟出一个样本点 ) 作为中心点 ;2 . ...
《写给程序员的数据挖掘实践指南》——1.2并不只是对象
本节书摘来自异步社区出版社《写给程序员的数据挖掘实践指南》一书中的第1章,第1.2节,作者:【美】Ron Zacharski(扎哈尔斯基),更多章节内容可以访问云栖社区“异步社区”公众号查看。 1.2并不只是对象 数据挖掘不仅仅只与对象推荐有关,也不只是帮助销售者卖掉更多的物品。考虑如下的例子。 1...
《python 与数据挖掘 》一 3.3 可变对象与不可变对象
本节书摘来自华章出版社《python 与数据挖掘 》一书中的第3章,第3.3节,作者张良均 杨海宏 何子健 杨 征,更多章节内容可以访问云栖社区“华章计算机”公众号查看。 3.3 可变对象与不可变对象 Python的所有对象可分为可变对象和不可变对象(见表3-1)。所谓可变对象是指,对象的内容可变,...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。

