
Transformer 和扩散模型的生成式 AI 实用指南(预览版)
原文:Hands-On Generative AI with Transformers and Diffusion Models 译者:飞龙 协议:CC BY-NC-SA 4.0 第一章:扩散模型 在 2020 年末,一个名为扩散模型的鲜为人知的模型类别开始在机器学习领域引起轰动。研究人员找出了如何...
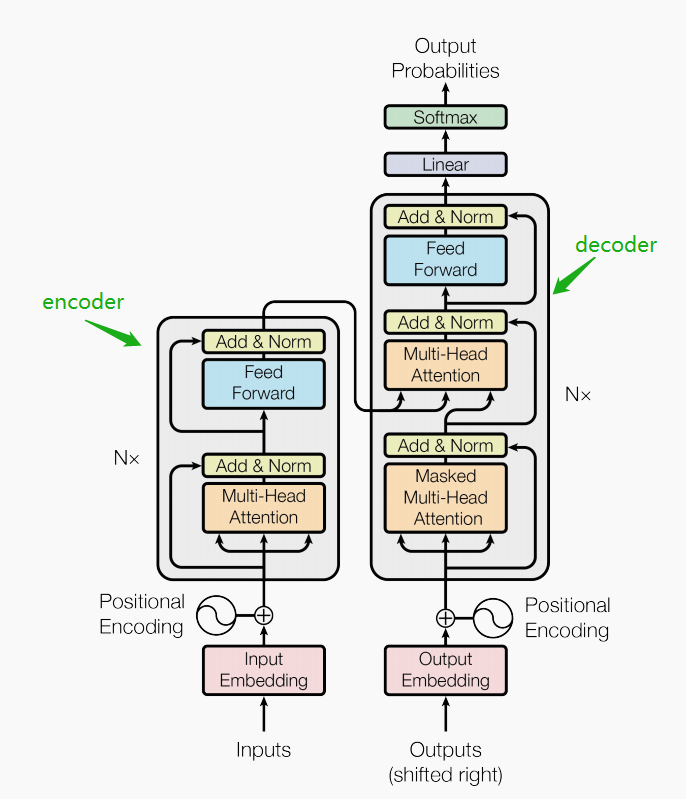
极智AI | 变形金刚大家族Transformer ViT CLIP BLIP BERT模型结构
大家好,我是极智视界,本文整理介绍一下 Transformer ViT CLIP BLIP BERT 模型结构。这几个模型都跟 变形金刚 相关,Transformer 是最开始的,然后像 ViT、CLIP、BLIP、BERT 都会用到 Transformer Encoder 模块,其中 ViT、CL...


【计算机视觉】最新综述:南洋理工和上海AI Lab提出基于Transformer的视觉分割综述
一、导读 SAM (Segment Anything )作为一个视觉的分割基础模型,在短短的3个月时间吸引了很多研究者的关注和跟进。如果你想系统地了解SAM背后的技术,并跟上内卷的步伐,并能做出属于自己的SAM模型,那么接下这篇Transformer-Based的Segmentation Surve...

NTU、上海AI Lab整理300+论文:基于Transformer的视觉分割最新综述出炉
SAM (Segment Anything )作为一个视觉的分割基础模型,在短短的 3 个月时间吸引了很多研究者的关注和跟进。如果你想系统地了解 SAM 背后的技术,并跟上内卷的步伐,并能做出属于自己的 SAM 模型,那么接下这篇 Transformer-Based 的 Segmentation S...
Transformer六周年:当年连NeurIPS Oral都没拿到,8位作者已创办数家AI独角兽
有的人加入 OpenAI,有的人成立创业公司,也有的坚守谷歌 AI。当年正是他们共同开启了今天的 AI 大发展时代。从 ChatGPT 到 AI 画图技术,人工智能领域最近的这波突破或许都要感谢一下 Transformer。今天是著名的 transformer 论文提交六周年的日子。论文链接:htt...
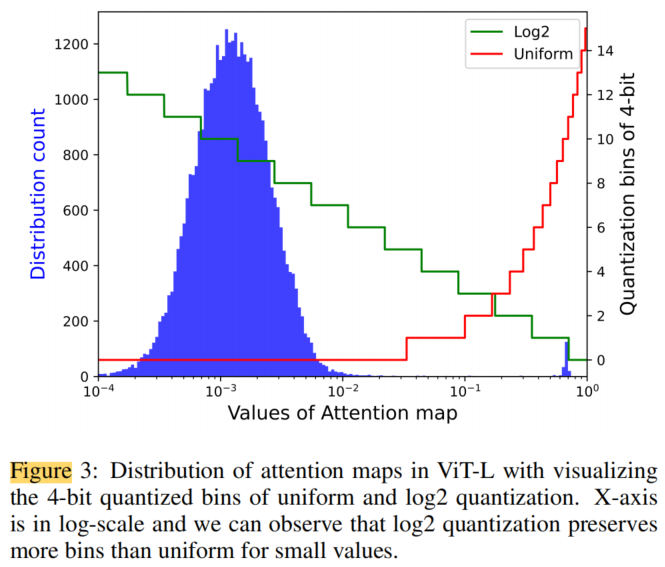
首个完全量化Vision Transformer的方法FQ-ViT | AI大模型落地加速还会远吗?(二)
3.3、用于Softmax量化的Log Int Softmax多头自注意力(MSA)是基于Transformer的架构中最重要的组件之一,但由于Token数量的二次复杂性,即图像分辨率除以Patch size,它被认为是资源最密集的组件。随着模型性能被证明受益于更高的分辨率和更小的Patch siz...

首个完全量化Vision Transformer的方法FQ-ViT | AI大模型落地加速还会远吗?(一)
模型量化显著降低了模型推理的复杂性,并已被广泛用于现实应用的部署。然而,大多数现有的量化方法主要是在卷积神经网络(CNNs)上开发的,当应用于全量化的Vision Transformer时,会出现严重的退化。在这项工作中证明了这些困难中的许多是由于LayerNorm输入中的严重通道间变化而出现的,并...

为内存塞不下Transformer犯愁?OpenAI应用AI研究负责人写了份指南(3)
为了更好地处理长序列数据,Scaling Transformer 进一步配备了来自 Reformer 的 LSH(局部敏感哈希)注意力和 FFN 块循环,从而产生了 Terraformer 模型。混合专家系统 MoE专家混合系统 (MoE) 模型是一种专家网络的集合,每个样本仅激活网络的一个子集来获...

为内存塞不下Transformer犯愁?OpenAI应用AI研究负责人写了份指南(2)
为了推动 N:M 结构稀疏化,需要将一个矩阵的列拆分为 M 列的多个 slide(也称为 stripe),这样可以很容易地观察到每个 stripe 中的列顺序和 stripe 的顺序对 N:M 稀疏化产生的限制。Pool 和 Yu 提出了一种迭代式的贪心算法来寻找最优排列,使 N:M 稀疏化的权重幅...

为内存塞不下Transformer犯愁?OpenAI应用AI研究负责人写了份指南(1)
本文是一篇综述性的博客,探讨总结当下常用的大型 transformer 效率优化方案。大型 Transformer 模型如今已经成为主流,为各种任务创造了 SOTA 结果。诚然这些模型很强大,但训练和使用起来代价非常昂贵。在时间和内存方面存在有极高的推理成本。概括来说,使用大型 Transforme...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









