华为诺亚开源首个亿级中文多模态数据集-悟空,填补中文NLP社区一大空白
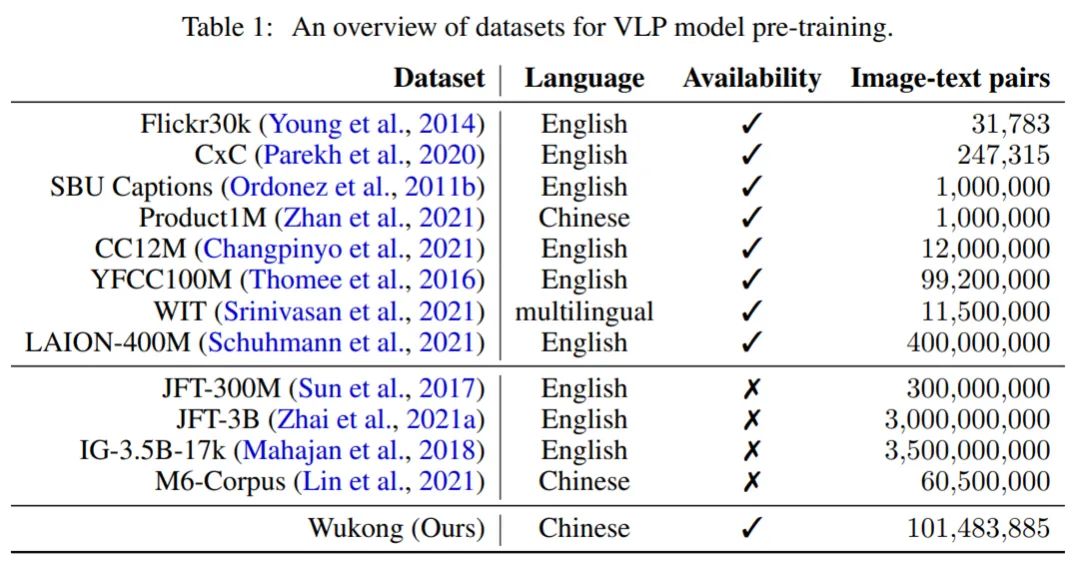
华为诺亚方舟实验室的研究者提出了一个大规模的中文的跨模态数据库 ——「悟空」,并在此基础上对不同的多模态预训练模型进行基准测试,有助于中文的视觉语言预训练算法开发和发展。在大数据上预训练大规模模型,对下游任务进行微调,已经成为人工智能系统的新兴范式。BERT 和 GPT 等模型在 NLP 社区中越来...

这个开源数据集要在全球扩大中文NLP影响力,你也能来做贡献!
千言的升级重点聚焦大模型时代的机遇和挑战。「千言」是由百度联合中国计算机学会、中国中文信息学会共同发起的面向自然语言处理的开源数据集项目,旨在推动中文信息处理技术的进步。近日,在 2021 年 12 月 12 日的 WAVE SUMMIT+2021 深度学习开发者峰会上,清华大学长聘副教授黄民烈作了...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子




最佳实践




