
全面超越ViT,美团、浙大等提出视觉任务统一架构VisionLLAMA
在人工智能的浪潮中,视觉任务的处理一直是技术进步的重要推动力。传统的卷积神经网络(CNN)在图像识别、分割和生成等领域取得了令人瞩目的成就,但随着Transformer模型在自然语言处理(NLP)领域的突破,人们开始期待这种基于自注意力机制的架构能在视觉领域同样大放异彩。在这样的背景下,美团、浙江大...
7 Papers & Radios | 谷歌下一代AI架构Pathways论文放出;何恺明组只用ViT做主干进行目标检测(2)
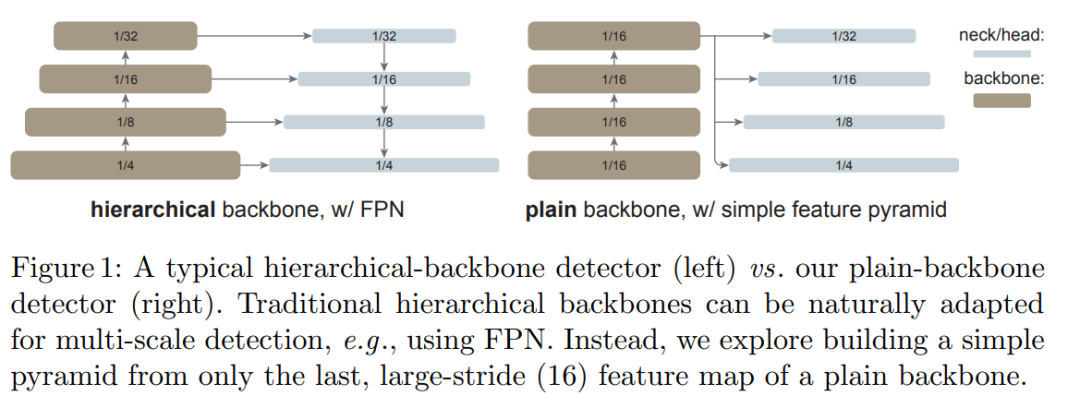
推荐:39 亿参数模型公开可用,采样速度 7 倍提升,残差量化生成图片入选 CVPR'22。论文 4:Exploring Plain Vision Transformer Backbones for Object Detection作者:Yanghao Li 、 Hanzi Mao 等论文链接:ht...

7 Papers & Radios | 谷歌下一代AI架构Pathways论文放出;何恺明组只用ViT做主干进行目标检测(1)
本周论文包括谷歌放出下一代 AI 架构 Pathways 论文;何恺明组最新论文等研究。目录Training-free Transformer Architecture Search PATHWAYS: ASYNCHRONOUS DISTRIBUTED DATAFLOW FOR ML&nb...
一文梳理视觉Transformer架构进展:与CNN相比,ViT赢在哪儿?(2)
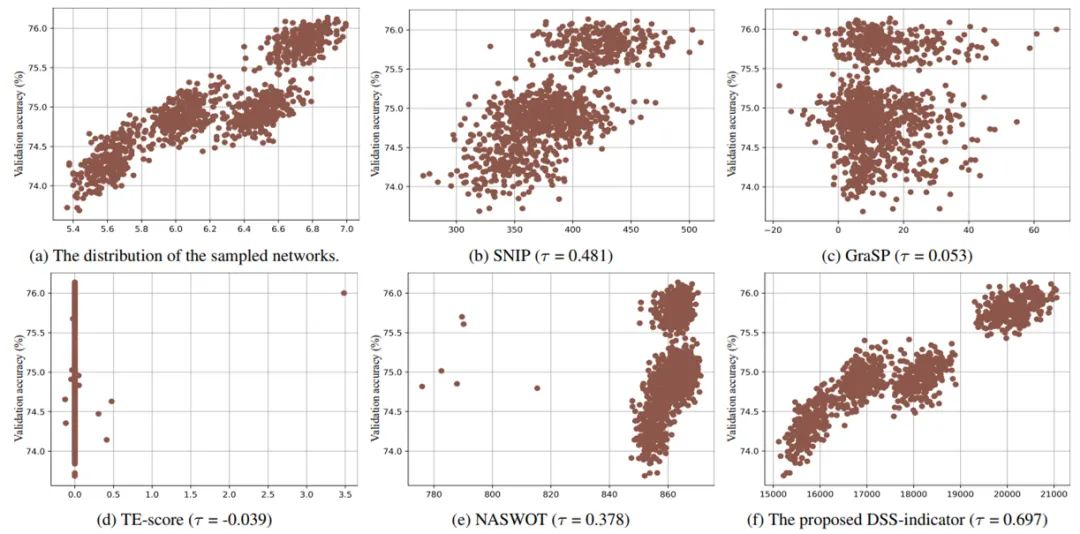
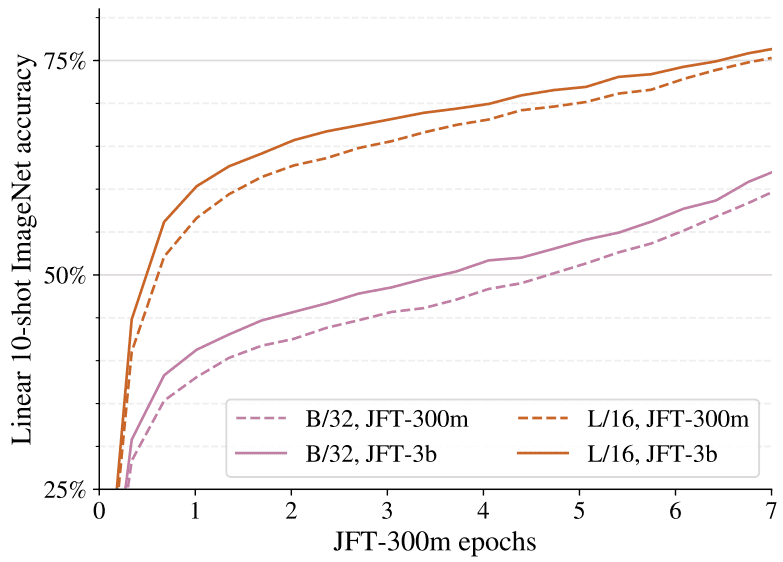
Scaling 视觉 Transformer深度学习和规模是相关的。事实上,规模是很多 SOTA 实现的关键因素。在这项研究中,来自 Google Brain Research 的作者训练了一个稍微修改过的 ViT 模型,它有 20 亿个参数,并在 ImageNet 上达到了 90.45 % 的 t...

一文梳理视觉Transformer架构进展:与CNN相比,ViT赢在哪儿?(1)
Transformer 近年来已成为视觉领域的新晋霸主,这个来自 NLP 领域的模型架构在 CV 领域有哪些具体应用?。Transformer 作为一种基于注意力的编码器 - 解码器架构,不仅彻底改变了自然语言处理(NLP)领域,还在计算机视觉(CV)领域做出了一些开创性的工作。与卷积...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐

社区圈子




最佳实践




