432.4 FPS 快STDC 2.84倍 | LPS-Net 结合内存、FLOPs、CUDA实现超快语义分割模型(二)
3、实验3.1、Lightweight Designs3.2、SOTA对比3.3、速度对比3.4、可视化对比4、参考[1].Lightweight and Progressively-Scalable Networks for Semantic Segmentation5、推荐阅读YOLOU开源 |...

432.4 FPS 快STDC 2.84倍 | LPS-Net 结合内存、FLOPs、CUDA实现超快语义分割模型(一)
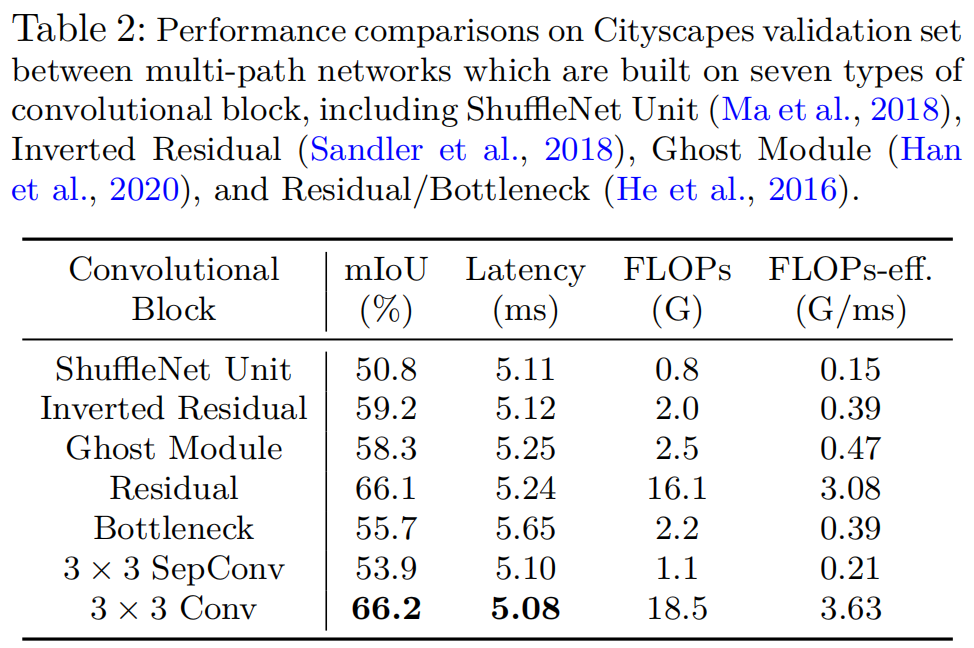
多尺度学习框架被认为是促进语义分割的一类模型。然而,这个问题并不想象的那么轻描淡写,特别是对于现实应用的部署,这通常需要高效率的推理延迟。在本文中,作者从轻量级语义分割的角度彻底分析了卷积块的设计(卷积类型和卷积中的通道数)以及跨多个尺度的交互方式。通过如此深入的比较,作者总结出3个原则...
链表与内存--头节点和链表分割
上篇写到了链表,后来发现自己对链表的理解还有些偏差,重新做了下链表测试,优化了相关代码。主要改动的地方是:之前理解的链表为一个节点一个节点串联起来,后来查看资料,发现如果给链表增加一个空节点,使用起来会更加方便。也就是说,链表表头的第一个节点只有地址,没有实际数据,当然我们也可以给他填充上一些数据比...

432.4 FPS 快STDC 2.84倍 | LPS-Net 结合内存、FLOPs、CUDA实现超快语义分割模型
多尺度学习框架被认为是促进语义分割的一类模型。然而,这个问题并不想象的那么轻描淡写,特别是对于现实应用的部署,这通常需要高效率的推理延迟。在本文中,作者从轻量级语义分割的角度彻底分析了卷积块的设计(卷积类型和卷积中的通道数)以及跨多个尺度的交互方式。通过如此深入的比较,作者总结出3个原则...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐


最佳实践


