
Sqoop与Spark的协作:高性能数据处理
将Sqoop与Spark协作是实现高性能数据处理的关键步骤之一。Sqoop用于将数据从关系型数据库导入到Hadoop生态系统中,而Spark用于大规模数据处理和分析。本文将深入探讨如何使用Sqoop与Spark协作,提供详细的步骤、示例代码和最佳实践,以确保能够成功实现高性能数据处理。 什么是Sqo...
继Spark之后,UC Berkeley 推出新一代高性能深度学习引擎——Ray(2)
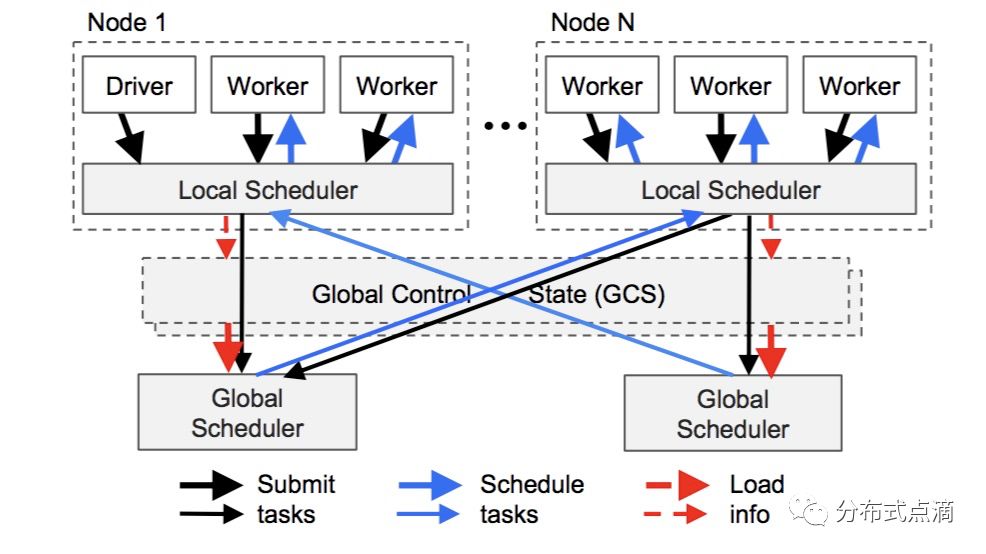
应用层应用层包括三种类型的进程:驱动进程(Driver):用来执行用户程序。工作进程(Worker):用来执行 Driver 或者其他 Worker 指派的任务(remote functions,就是用户代码中装饰了`@ray.remote` 的那些函数)的无状...

继Spark之后,UC Berkeley 推出新一代高性能深度学习引擎——Ray(1)
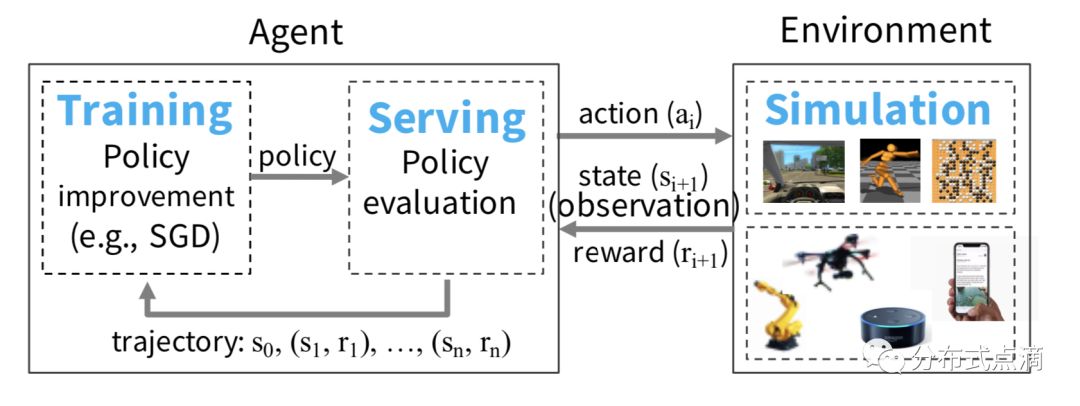
导读继 Spark 之后,UC Berkeley AMP 实验室又推出一重磅高性能AI计算引擎——Ray,号称支持每秒数百万次任务调度。那么它是怎么做到的呢?在试用之后,简单总结一下:极简 Python API 接口:在函数或者类定义时加上 ray.remote 的装饰器并做一些微小改变,...
大数据和AI | 基于Spark的高性能向量化查询引擎
嘉宾:范文臣Databricks 开源组技术主管,Apache Spark Committer、PMC成员,Spark开源社区核心开发之一。 视频地址:https://developer.aliyun.com/live/245461正文:Databricks最新开发的一款基于Spark的高性能向量化...
请问使用spark的时候,如果使用高性能64核高内存的阿里云服务器,用哪种模式运行比较好?
在64核高内存的阿里云服务器中使用spark的时候,用Local模式的64线程运行比较好还是用standalone将多个子节点设置在本地好? 遇到了同样的问题,在CSDN看到了,希望阿里云团队能够给出正确、标准的答案~请查看
【Hadoop Summit Tokyo 2016】基于Spark的高性能时空轨迹分析
本讲义出自YongHua (Henry) Zeng在Hadoop Summit Tokyo 2016上的演讲,主要分享了基于Spark的高性能时空轨迹分析的相关背景、架构以及技术设计,在技术设计方面主要讲解了大数据平台的设计、数据治理的设计、算法模型以及Spark轨迹计算等内容,最后还对于高性能时空...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark大数据计算
- apache spark client
- apache spark模式
- apache spark yarn
- apache spark MaxCompute
- apache spark like
- apache spark应用
- apache spark SQL
- apache spark原理
- apache spark产品
- apache spark streaming
- apache spark Apache
- apache spark数据
- apache spark Hadoop
- apache spark大数据
- apache spark rdd
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark分析
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark flink
- apache spark Scala
- apache spark任务
- apache spark程序