大数据开发岗面试30天冲刺 - 日积月累,每日五题【Day01】——Hive1
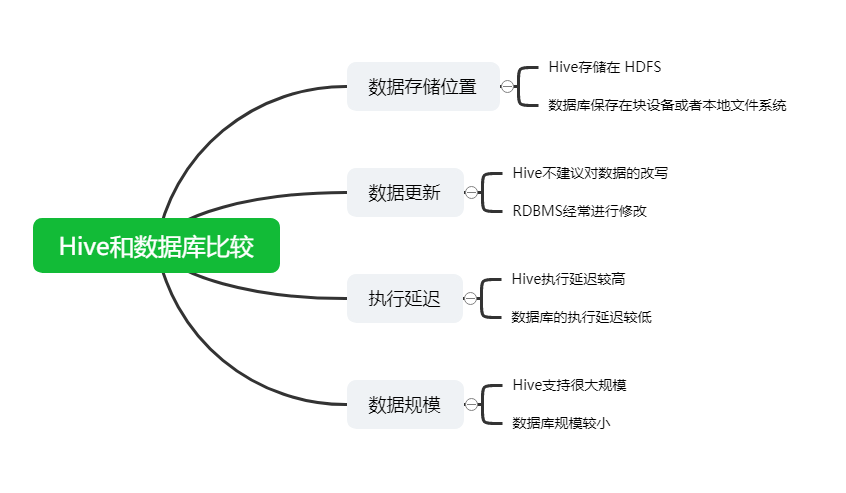
面试题01、 请说下Hive和数据库的区别Hive 和数据库除了拥有类似的查询语言,再无类似之处。1)数据存储位置Hive 存储在 HDFS 。数据库将数据保存在块设备或者本地文件系统中。2)数据更新Hive中不建议对数据的改写。而数据库中的数据通常是需要经常进行修改的,3)执行延迟Hive 执行延...
Hadoop Hive面试连环炮 2
6 hive常用的优化6.1 Fetch抓取(Hive可以避免进行MapReduce) Hive中对某些情况的查询可以不必使用MapReduce计算。例如:SELECT * FROM employees;在这种情况下,Hive可以简单地读取employee对应的存储目录下的文件,然后输出查询结果到控...


Hadoop Hive面试连环炮 1
1 hive的介绍 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。 本质是将SQL转换为MapReduce程序。 主要用途:用来做离线数据分析,比直接用MapReduce开发效率更高。2 hive的架构用户接口:包括 CLI JDBC...

【面试必问】窗口函数全解-HIVE
这是我的第30篇原创其实很讨厌有人问窗口函数,因为窗口函数解决的是我在刚开始工作时遇到的问题。因为是BI工程师出身,从业开始就在做各种排名、同比、环比、帕累托占比、当前最大等各种乱七八糟的表格需求。什么是窗口函数?网上很多数据都写的乱七八糟,搞得好像你越看不懂就显得他越厉害一样。来吧,保证你只要会s...
不需要编写代码,也能成为Hive SQL面试高手?ChatGPT告诉你...
当你面对 Hive SQL 面试时,不仅需要掌握 SQL 语言的基本知识,还需要熟练掌握 Hive SQL 的一些高级特性,比如窗口函数、分区等等。对于初学者而言,写出高效的 Hive SQL 代码往往是一件困难的事情,而这恰恰是面试官最为看重的。但是,你不必担心!现在,有一种神奇的工...

【Hadoop技术篇】hive的优化,经典面试
目录Map Join作用触发条件Bucket-Map Join作用触发条件SMB Join (sort merge bucket)作用触发条件Join-Skew关联查询时数据倾斜运行时优化编译时优化Unoin优化GroupBy-Skew统计时数据倾斜Map先行打散MR Job随机数打散M...
大数据面试-hive
一、hive表关联查询,如何解决数据倾斜问题?1)倾斜原因:map 输出数据按 key Hash 的分配到 reduce 中,由于 key 分布不均匀、业务数据本身的特、建表时考虑不周、等原因造成的 reduce 上的数据量差异过大。(1)key 分布不均匀;(2)业务数...
数仓面试高频考点--解决hive小文件过多问题
小文件产生原因hive 中的小文件肯定是向 hive 表中导入数据时产生,所以先看下向 hive 中导入数据的几种方式直接向表中插入数据insert into table A values (1,'zhangsan',88),(2,'lisi',61);这种方式每次插入时都会产生一个文件,多次插入少...
【最全的大数据面试系列】Hive面试题大全
🚀 作者 :“大数据小禅”🚀 专栏简介 :本专栏主要分享收集的大数据相关的面试题,涉及到Hadoop,Spark,Flink,Zookeeper,Flume,Kafka,Hive,Hbase等大数据相关技术。大数据面试专栏地址...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。



