[帮助文档] 如何使用商品评价解析的增量训练功能
商品评价解析-增量训练。
[帮助文档] 如何训练文本关系抽取的模型
文本关系抽取-模型训练。

[帮助文档] 如何训练文本分类模型
在训练模型这一步,您不需要关心任何模型的实现细节,只要选择相应的模型就好了。这也是我们 NLP 自学习平台的初衷,即帮助用户快速搭建一套解决问题的算法模型,用户只需关心模型的输入输出就好了。进入到模型中心,然后点击创建模型:在模型类型这里,我们提供了多种模型供选择,我们无法承诺一种模型一定比另一种模...
![NLP文本匹配任务Text Matching [无监督训练]:SimCSE、ESimCSE、DiffCSE 项目实践](https://ucc.alicdn.com/fnj5anauszhew_20230814_eab7fce758074688ab83953012839cc1.png)
NLP文本匹配任务Text Matching [无监督训练]:SimCSE、ESimCSE、DiffCSE 项目实践
NLP文本匹配任务Text Matching [无监督训练]:SimCSE、ESimCSE、DiffCSE 项目实践 文本匹配多用于计算两个文本之间的相似度,该示例会基于 ESimCSE 实现一个无监督的文本匹配模型的训练流程。文本匹配多用于计算两段「自然文本」之间的「相似度」。 例如,在搜索引擎中...
![NLP文本匹配任务Text Matching [有监督训练]:PointWise(单塔)、DSSM(双塔)、Sentence BERT(双塔)项目实践](https://ucc.alicdn.com/fnj5anauszhew_20230814_88e131726dc44ae19e24afecf4292967.png)
NLP文本匹配任务Text Matching [有监督训练]:PointWise(单塔)、DSSM(双塔)、Sentence BERT(双塔)项目实践
NLP文本匹配任务Text Matching [有监督训练]:PointWise(单塔)、DSSM(双塔)、Sentence BERT(双塔)项目实践 0 背景介绍以及相关概念 本项目对3种常用的文本匹配的方法进行实现:PointWise(单塔)、DSSM(双塔)、Sentence BERT(双塔)...
NLP之word2vec:利用 Wikipedia Text(中文维基百科)语料+Word2vec工具来训练简体中文词向量(二)
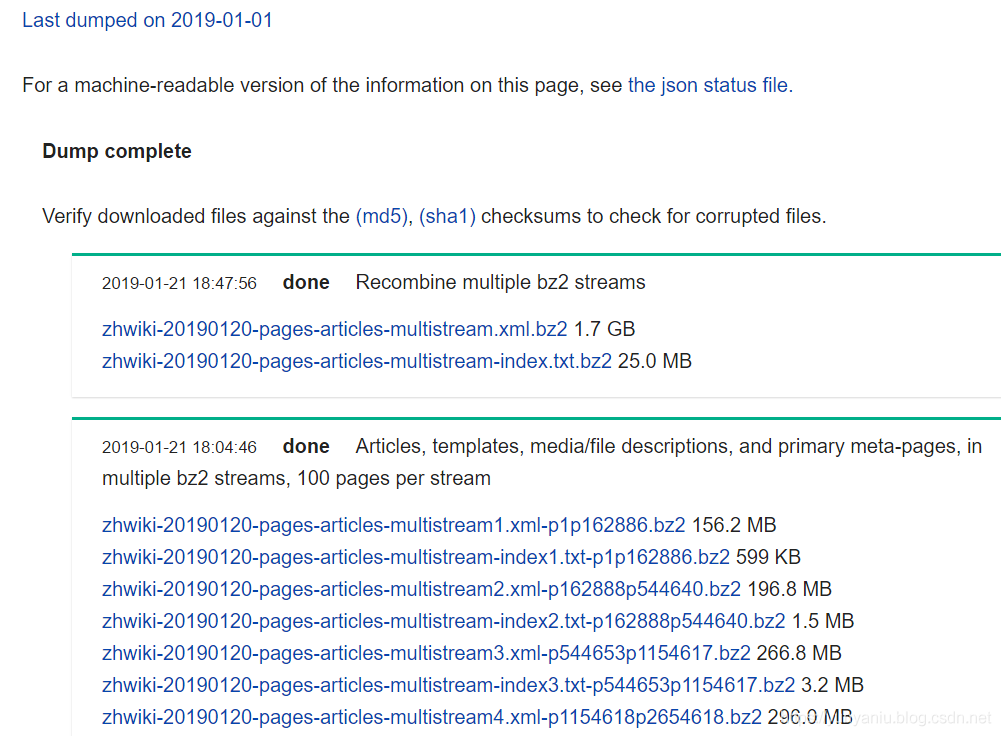
实现代码对下边文件代码的说明#We create word2vec model use wiki Text like this https://dumps.wikimedia.org/zhwiki/20161001/zhwiki-20161001-pages-articles-multistream...
NLP之word2vec:利用 Wikipedia Text(中文维基百科)语料+Word2vec工具来训练简体中文词向量(一)
输出结果后期更新……最后的modelword2vec_wiki.model.rar设计思路后期更新……1、Wikipedia Text语料来源Wikipedia Text语料来源及其下载:zhwiki dump progress on 20190120 其中...
[帮助文档] 如何训练对话文本分类的模型
完成了数据集的构建,就可以开始模型的训练了。回到创建的项目,切换至“模型中心”并点击“创建模型”。进入创建模型后,通过自学习平台,您无需关心任何模型的实现细节,只要选择相应的模型就可以开始训练(当前只有一种默认模型可选,后续可能增加)。首先请填入模型的名称。点击添加训练数据的按钮,可以找到您已经标注...
[帮助文档] 如何训练合同要素抽取的模型
完成了数据集的构建,就可以开始模型的训练了。回到创建的项目,切换至“模型中心”并点击“创建模型”。进入创建模型后,通过自学习平台,您无需关心任何模型的实现细节,只要选择相应的模型就可以开始训练(当前只有一种默认模型可选,后续可能增加)。首先请填入模型的名称。点击添加训练数据的按钮,可以找到您已经标注...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子




最佳实践




