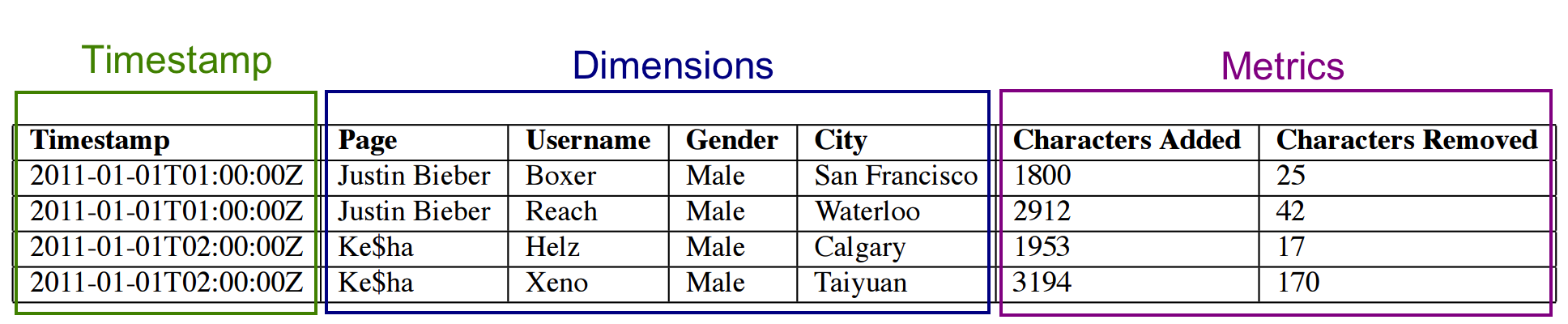
Apache Druid 底层的数据存储
导读:首先你将通过这篇文章了解到 Apache Druid 底层的数据存储方式。其次将知道为什么 Apache Druid 兼具数据仓库,全文检索和时间序列的特点。最后将学习到一种优雅的底层数据文件结构。今日格言:优秀的软件,从模仿开始的原创。了解过 Apache Druid 或之前看过本系列前期文...

阿里云 X Apache Doris X Zilliz沙龙回顾|大模型时代的数据存储与分析
前言大模型的 AIGC 场景在近年来引起了大众的广泛关注。人们不再满足于简单的对话,而是开始探索更深入的行业应用场景,如通过自然语言实现SQL的数据分析,从而降低数据分析使用门槛,再比如利用个人或企业专属数据,构建专属智能知识库和在线智能客服。在这些场景中,有一个至关重要的前提,...

Apache HBase中应用程序将数据存储到哪呢?由什么组成?
Apache HBase中应用程序将数据存储到哪呢?由什么组成?
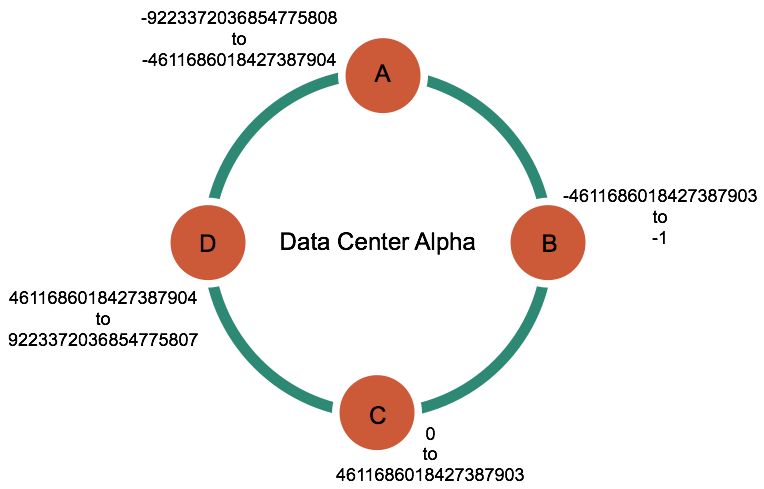
Apache Cassandra 数据存储模型
我们在《Apache Cassandra 简介》文章中介绍了 Cassandra 的数据模型类似于 Google 的 Bigtable,对应的开源实现为 Apache HBase,而且我们在 《HBase基本知识介绍及典型案例分析》 文章中简单介绍了 Apache HBase 的数据模型。按照这个思...
将Apache Flink中的关系数据存储为状态并通过属性查询
我有一个包含表T1(id,name,age)和T2(id,subject)的数据库。Flink使用诸如debezium之类的东西从事件流接收来自数据库的所有更新。这些表被彼此相关的和所需的数据可以由被提取接合 T1与T2上的id。目前,数据库的整个状态存储在Flink MapState中,其中id为...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子







Apache您可能感兴趣
- Apache入门
- Apache tomcat
- Apache web
- Apache api
- Apache客户端
- Apache curator
- Apache java
- Apache zookeeper
- Apache节点
- Apache集群
- Apache flink
- Apache配置
- Apache rocketmq
- Apache dubbo
- Apache安装
- Apache php
- Apache服务器
- Apache linux
- Apache spark
- Apache开发
- Apache报错
- Apache服务
- Apache微服务
- Apache从入门到精通
- Apache hudi
- Apache mysql
- Apache doris
- Apache日志
- Apache kafka