机器学习如何做到疫情可视化——疫情数据分析与预测实战
一、问题说明1、爬取中国、美国、巴西、印度、俄罗斯、法国、英国、土耳其、阿根廷、哥伦比亚、日本等11个国家以及中国31个省(自治区、直辖市)在2022.0101-2022.06.19的新冠疫情数据。如果对数据爬虫技术不熟悉,可使用data文件中提供的数据,其中中国各省数据为confirmedCoun...
机器学习系列(4)_数据分析之Kaggle鸢尾花iris(下)
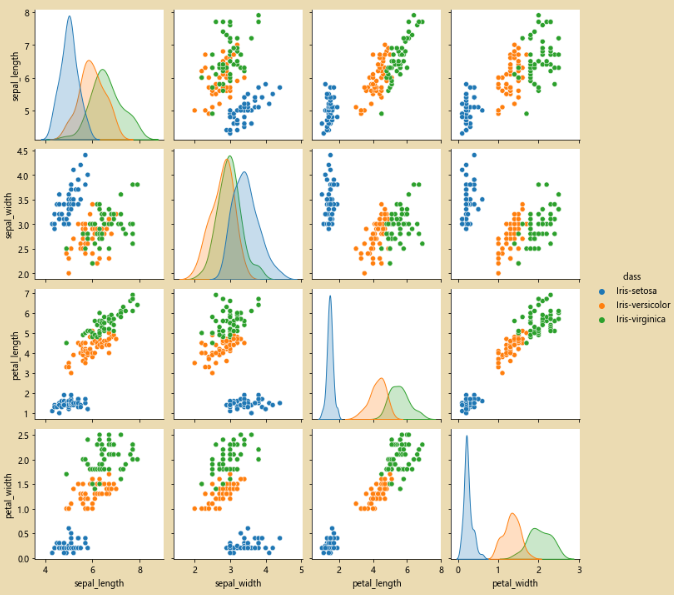
三、决策树和随机森林1、绘制图形%matplotlib inline import matplotlib.pyplot as plt import seaborn as sb sb.pairplot(iris_data.dropna(),hue='class') 绘制小提琴图:plt.figure(...


机器学习系列(4)_数据分析之Kaggle鸢尾花iris(上)
我们要解决的问题如下:已知鸢尾花iris分为三个不同的类型:山鸢尾花Setosa、变色鸢尾花Versicolor、韦尔吉尼娅鸢尾花Virginica,这个分类主要是依据鸢尾花的花萼长度、宽度和花瓣的长度、宽度四个指标(也可能还有其他参考)。我们并不知道具体的分类标准,但是植物学家已经为150朵不同的...
机器学习系列(2)_数据分析之Kaggle电影TMDB5000(下)
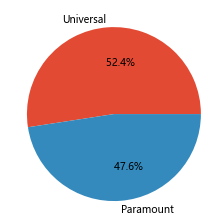
四、 Universal和Paramount两家影视公司的对比情况如何?# 对比两家电影公司的电影发行情况 # 对电影公司的数据进行整理 moviesdf['prodcompanies']=moviesdf['production_companies'].apply(json.loads) movi...
机器学习系列(2)_数据分析之Kaggle电影TMDB5000(上)
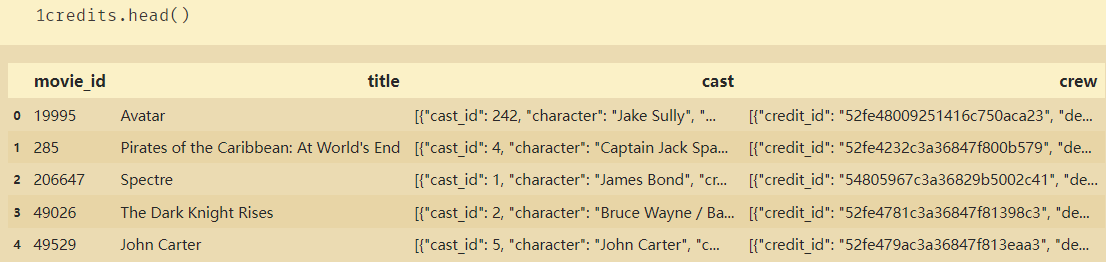
一、数据整理1、合并+处理缺失值# tmdb_5000_movies.csv budget :电影成本 genres:风格列表,按|分隔,最多5种风格 homepage:电影首页URL id :电影ID keywords:电影关键词,按|分隔,最多5种关键词 o...
机器学习系列(1)_数据分析之Kaggle泰坦尼克之灾(上)
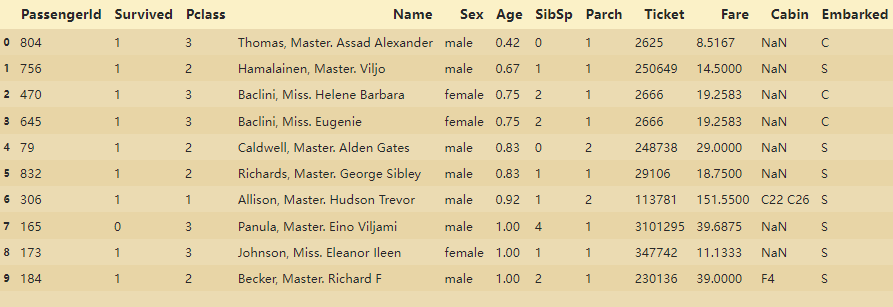
一、数据的初步探索import seaborn as sns import numpy as np import pandas as pd import matplotlib as mpl import matplotlib.pyplot as plt %matplotlib inline # 有时...
机器学习系列(1)_数据分析之Kaggle泰坦尼克之灾(下)
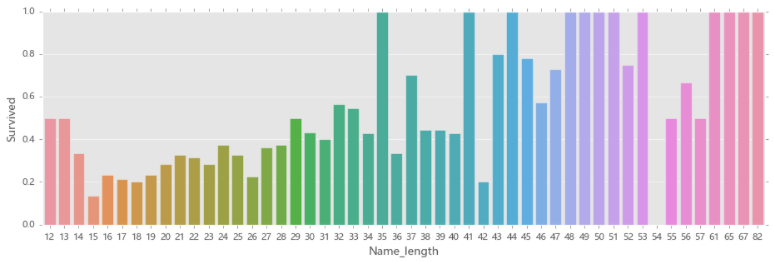
6.名称长度与存活率的关系## 04.08 名称的长度对生存率的影响 fig,axis1=plt.subplots(1,1,figsize=(14,4)) train_data['Name_length']=train_data['Name'].apply(len) # 这里年龄出现小数,但是使用....
python 数据分析机器学习sklearn包快速上手
1 sklearn自带数据集sklearn中带有很多数据集from sklearn import datasets diabetes=datasets.load_diabetes() X=diabetes.data y=diabetes.target X.shape X[:5]y[:10]2 使用s...
收藏 | 数据分析师最常用的10个机器学习算法!
在机器学习领域,有种说法叫做“世上没有免费的午餐”,简而言之,它是指没有任何一种算法能在每个问题上都能有最好的效果,这个理论在监督学习方面体现得尤为重要。 举个例子来说,你不能说神经网络永远比决策树好,反之亦然。模型运行被许多因素左右,例如数据集的大小和结构。 因此,你应该根据你的问题尝试许多不同的...
独家 | 数据分析@爱可可-爱生活是否在用机器学习算法运营微博
爱可可老师的微博账号创建于2010年底,初期的微博内容充满了人情味,分享了爱女出生的喜悦、行业资讯、学习资料,以及人生工作感悟。 热词分析显示,爱可可微博是从2014年底开始热度变高,此时该账号已是每日凌晨四五点起分享大量的学习资料。 在分享资料的间隙,爱可可老师也会发布一些个人见解,其中有一条微博...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子




最佳实践




