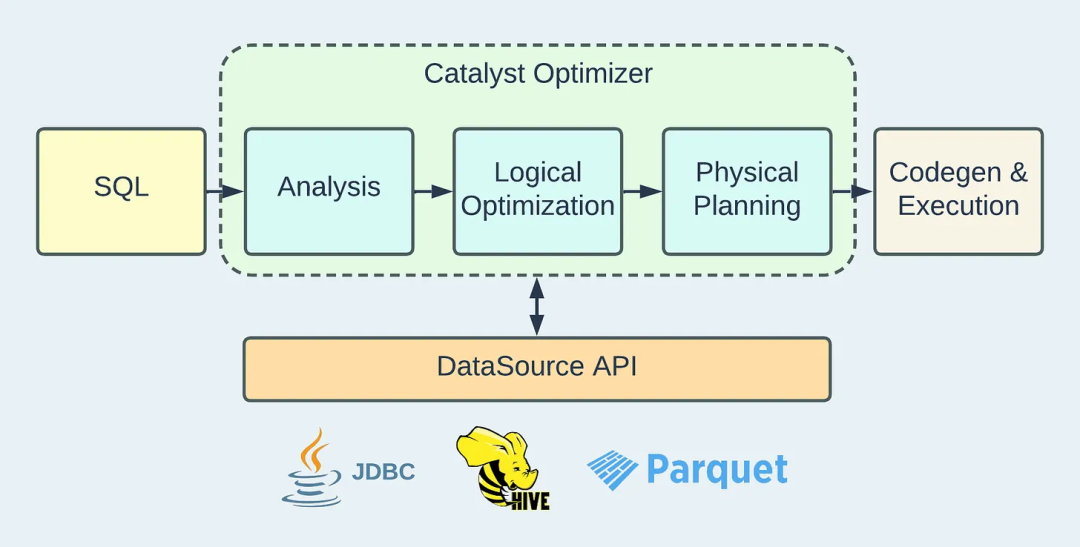
Apache Hudi从零到一:深入研究读取流程和查询类型(二)
在上一篇文章中,我们讨论了 Hudi 表中的数据布局,并介绍了 CoW 和 MoR 两种表类型,以及它们各自的权衡。在此基础上我们现在将探讨 Hudi 中的读取操作是如何工作的。 有多种引擎(例如 Spark、Presto 和 Trino)与 Hudi 集成来执行分析查询。尽管集成 API 可能有所...
Apache Mina高性能通信框架研究邮件列表.
一直到现在,我都没有发现国内讨论Apache Mina高性能通信框架研究的好地方。我也经常被网友问起一些有关Apache Mina高性能通信框架研究相关的问题,有些问题是很基本的网络编程问题,而其中的某些讨论,对于我本身也是很有帮助的,我觉得有必要将这些讨论信息提供出来。想来想去,还是觉得使用邮件列...

大数据产品管理平台Apache Ambari研究
1、环境准备1.1、配置时间同步centos7开始使用chrony进行始终同步,安装chrony并配置始终同步,设置为开机启动yum -y install chrony #系统默认已经安装,如未安装,请执行以下命令安装1.2、配置主机名、映射设置主机名:[root@cdh1 ~]host...
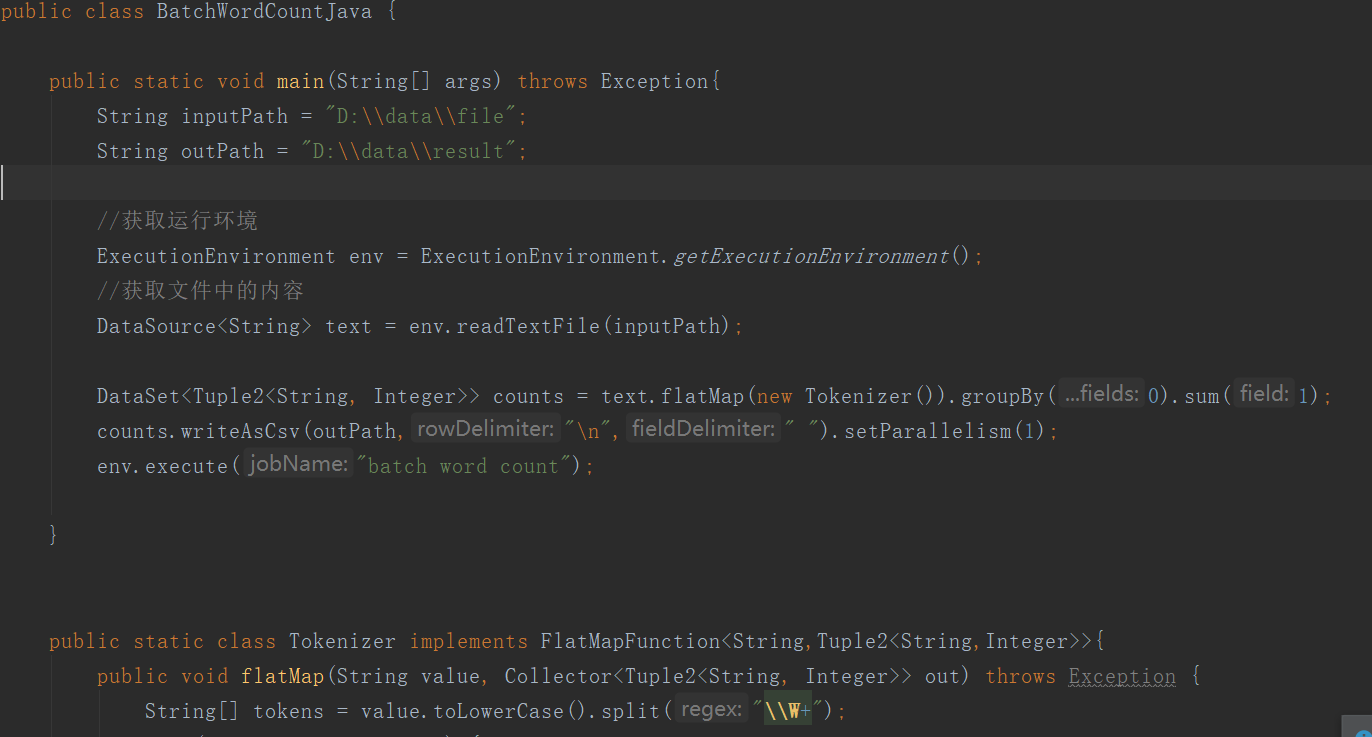
实时大数据计算引擎Apache Flink计算研究(二)
接上文,实时大数据计算引擎Apache Flink计算研究(一)8、Flink DataSetAPI数据源部分不但提供了流处理,还提供了批处理,流处理和批处理分属于不同的api基于文件readTextFile(path)基于集合fromCollection(Collection)算子部分Map:输入...

实时大数据计算引擎Apache Flink计算研究(一)
1、Flink local模式安装(Linux)1.在官网下载Flink,并解压到 /opt/software/flink-text/tar -zxvf flink-1.6.1-bin-hadoop27-scala_2.11.tgz2.解压成功后 local模式不需要添加额外配置...
Apache Beam研究报告
概述 本文不是一篇Beam的入门文档,不会介绍Beam的基本概念;而会主要探讨Beam的表达力,Beam的性能,以及Beam目前在业内的使用情况。面向的读者是那些想使用Beam作为自己公司操作大数据的统一API,但是还有所顾虑的人们。 表达力 离线 Beam里面有两个核心原语: ParDo: 来处理...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子







Apache您可能感兴趣
- Apache公网ip
- Apache负载
- Apache阿里云
- Apache数据库
- Apache服务器
- Apache请求
- Apache入门
- Apache tomcat
- Apache web
- Apache pdf
- Apache flink
- Apache配置
- Apache rocketmq
- Apache安装
- Apache php
- Apache dubbo
- Apache linux
- Apache spark
- Apache开发
- Apache报错
- Apache服务
- Apache微服务
- Apache从入门到精通
- Apache hudi
- Apache doris
- Apache mysql
- Apache日志
- Apache kafka