
【云计算与大数据技术】Spark实战项目之判别西瓜好坏(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~一、判别西瓜好坏西瓜是一种人们很喜欢的水果,是盛夏季节的一种解暑物品,西瓜可以粗略的分为好瓜和坏瓜,我们都希望购买到的西瓜是好的,这里给出判断西瓜好坏的两个特征,一个特 征是西瓜的糖度,另外一个特征是西瓜的密度,这两个数值都是0~1的小数,基于西瓜...
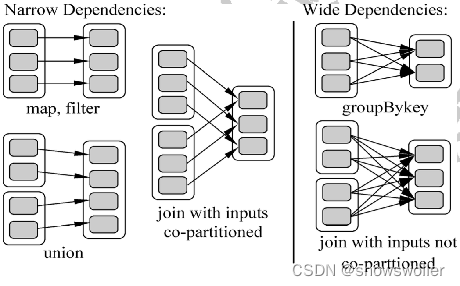
【云计算与大数据技术】Spark的解析(图文解释 超详细必看)
一、Spark RDDSpark是一个高性能的内存分布式计算框架,具备可扩展性,任务容错等特性,每个Spark应用都是由一个driver program 构成,该程序运行用户的 main函数 。Spark提供的一个主要抽象就是 RDD(Resilient Distributed Datasets),...


【云计算与大数据计算】分布式处理CPU多核、MPI并行计算、Hadoop、Spark的简介(超详细)
一、CPU多核和POISX Thread为了提高任务的计算处理能力,下面分别从硬件和软件层面研究新的计算处理能力在硬件设备上,CPU 技术不断发展,出现了SMP(对称多处理器)和 NUMA(非一致 性内存访问)两种高速处理的 CPU 结构 在软件层面出现了多进程和多线程编程。进程是内存资源管理单元,...
![Spark集群搭建记录 | 云计算[CentOS8] | Scala Maven项目访问Spark(local模式)实现单词计数(下)](https://ucc.alicdn.com/pic/developer-ecology/727799447e3d4bcf9a7390f4d6174fe0.png)
Spark集群搭建记录 | 云计算[CentOS8] | Scala Maven项目访问Spark(local模式)实现单词计数(下)
step6 创建scala object在src 目录下,我们创建一个scala object,右键src,然后:在里面写入代码逻辑,具体代码可以参考链接并根据实际情况对代码进行修改以上链接源代码:具体代码根据自己实际情况来进行修改import org.apache.spark.{SparkConf...
![Spark集群搭建记录 | 云计算[CentOS7] | Scala Maven项目访问Spark(local模式)实现单词计数(上)](https://ucc.alicdn.com/pic/developer-ecology/2709fe8f00b74df4a505e574de531d20.png)
Spark集群搭建记录 | 云计算[CentOS7] | Scala Maven项目访问Spark(local模式)实现单词计数(上)
写在前面本系列文章索引以及一些默认好的条件在 传送门要想完成Spark的配置,首先需要完成Hadoop&&Spark的配置Hadoop配置教程:链接若未进行明确说明,均按照root用户操作step1 下载Scala IDE本来在Eclipse 的Marketplace便可以下载,可是...
![Spark集群搭建记录 | 云计算[CentOS7] | Spark配置](https://ucc.alicdn.com/pic/developer-ecology/90e64d6ac22142ab8737dec13b6a53a3.png)
Spark集群搭建记录 | 云计算[CentOS7] | Spark配置
写在前面本系列文章索引以及一些默认好的条件在 传送门要想完成Spark的配置,首先需要完成Hadoop的配置Hadoop配置教程:链接若未进行明确说明,均按照root用户操作step1 Spark下载下载链接因为后续可能会涉及到很严重的版本问题,所以说在这里我们为了适配,选择2.4.0版本下载后放在...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark步骤
- apache spark访问外网
- apache spark Hadoop
- apache spark数据
- apache spark分析
- apache spark Python
- apache spark可视化
- apache spark数据处理
- apache spark可视化分析
- apache spark入门
- apache spark SQL
- apache spark streaming
- apache spark Apache
- apache spark rdd
- apache spark大数据
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark实战
- apache spark机器学习
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作