
【数据挖掘】离群点检测方法详解及Sklearn中异常检测方法实战(附源码 超详细)
需要源码请点赞关注收藏后评论区留言私信~~~离群点的检测离群点的检测方法很多,每种方法在检测时都会对正常数据对象或离群点作出假设,从所做假设的角度,离群点检测方法可以分为基于统计学的离群点检测、基于近邻的离群点检测、基于聚类以及基于分类的离群点检测基于统计学的离群点检测在基于统计学的离群点检测方法中...

【数据挖掘】密度聚类DBSCAN讲解及实战应用(图文解释 附源码)
需要源码请点赞关注收藏后评论区留言私信~~~基于密度的聚类基于划分和聚类和基于层次的聚类往往只能发现凸型的聚类簇,为了更好的发现任意形状的聚类簇,提出了基于密度的聚类算法算法原理基于密度的聚类算法的主要思想是:只要邻近区域的密度(对象或数据点的数目)超过某个阈值 ,就把它加到与之相近的聚类中。也就是...

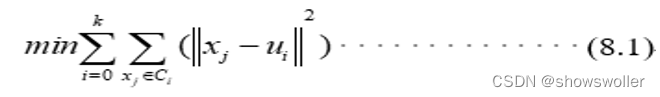
【数据挖掘】K-Means、K-Means++、ISODATA算法详解及实战(图文解释 附源码)
聚类分析无监督学习(Unsupervise Learning)着重于发现数据本身的分布特点。与监督学习(Supervised Learning)不同,无监督学习不需要对数据进行标记。从功能角度讲,无监督学习模型可以发现数据的“群落”,同时也可以寻找“离群”的样本。另外,对于特征维度非常高的数据样本,...
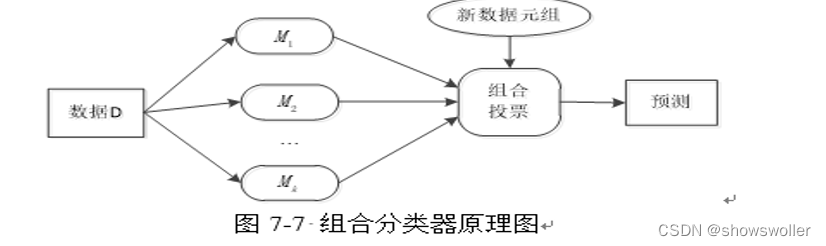
【数据挖掘】袋装、AdaBoost、随机森林算法的讲解及分类实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留言私信~~~组合分类组合分类器(Ensemble)是一个复合模型,由多个分类器组合而成。组合分类器往往比它的成员分类器更准确俗话说得好 三个臭皮匠顶过一个诸葛亮 此处也是如下 1:袋装袋装(Bagging)是一种采用随机有放回的抽样选择训练数据构造分类器进行组合的方法...
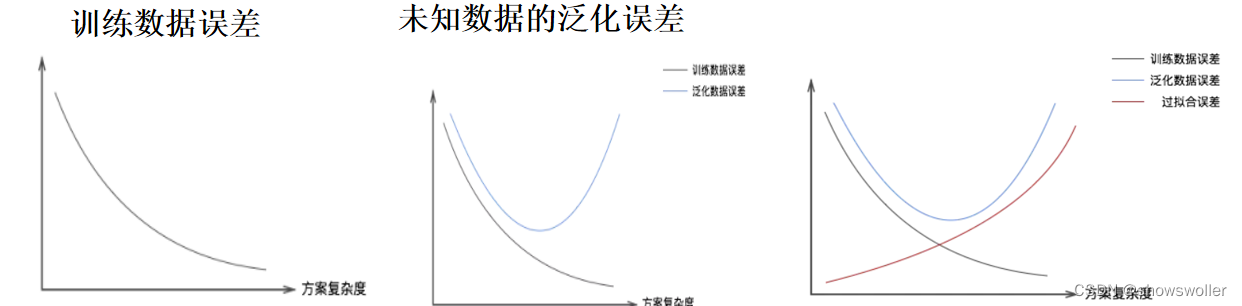
【数据挖掘】模型选择中正则化、交叉验证详解及实战应用(超详细 附源码)
模型选择当假设空间含有不同的复杂度的模型时,会面临模型选择(Model Selection)问题。我们希望所选择的模型要与真模型的参数个数相同,所选择的模型的参数向量与真模型的参数向量相近。然而,一味追求提高分类器的预测能力,所选择的模型的复杂度会比真模型要高,这种现象被称为过拟合(Over-fit...

【数据挖掘】分类器模型性能评估讲解及iris数据集评估实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留言私信~~~构建的分类器总是希望有较好的性能,如何评估分类器性能,需要一些客观的指标进行评判。比如,如何评估分类器的准确率(模型评估)以及如何在多个分类器中选择“最好的”一个分类器性能的度量训练分类器的目的是使学习到的模型对已知数据和未知数据都有很好的预测能力,不同的...
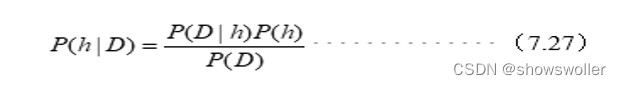
【数据挖掘】朴素贝叶斯分类讲解及对iris数据集分类实战(超详细 附源码)
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理(Bayes Theorem)为基础,采用了概率推理方法算法原理贝叶斯定理提供了一种计算假设概论的方法 朴素贝叶斯分类贝叶斯分类算法在处理文档分类核垃圾邮件过滤有较好的分类效果 高斯朴素贝叶斯分类原始的朴素贝叶斯分类只能处理离散数据,当处理连续变...

【数据挖掘】SVM原理详解及对iris数据集分类实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留言私信~~~支持向量机(Support Vetor Machine,SVM)由Vapnik等人于1995年首先提出,在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并推广到人脸识别、行人检测和文本分类等其他机器学习问题中SVM建立在统计学习理论的VC维理论和...
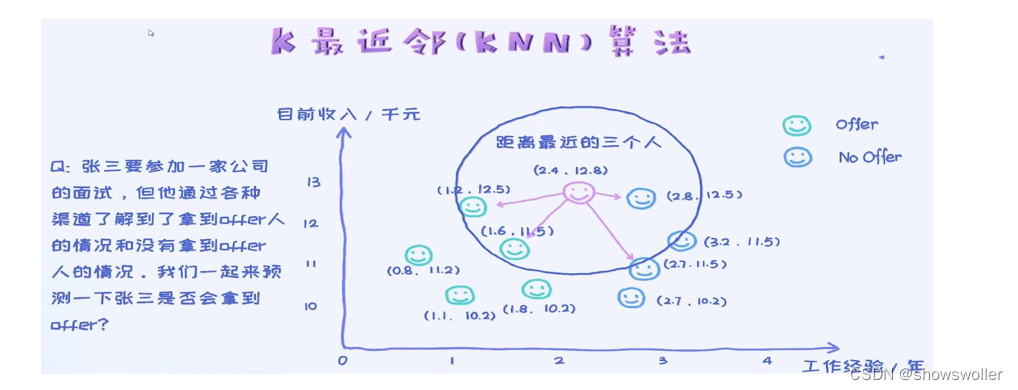
【数据挖掘】KNN算法详解及对iris数据集分类实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留言私信~~~K近邻(k-Nearest Neighbor Classification,KNN)算法是机器学习算法中最基础、最简单的算法之一,属于惰性学习法.惰性学习法和其他学习方法的不同之处在于它并不急于获得测试对象之前构造的分类模型,当接收一个训练集时,惰性学习法...

【数据挖掘】决策树中C4.5与CART算法讲解及决策树应用iris数据集实战(图文解释 附源码)
需要完整代码和PPT请点赞关注收藏后评论区留言私信~~~1:C4.5算法Quinlan在1993年提出了ID3的改进版本C4.5算法。它与ID3算法的不同主要有以下几点(1)分支指标采用增益比例,而不是ID3所使用的信息增益(2)按照数值属性值的大小对样本排序,从中选择一个分割点,划分数值属性的取值...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子

