【大数据技术Hadoop+Spark】Spark RDD创建、操作及词频统计、倒排索引实战(超详细 附源码)
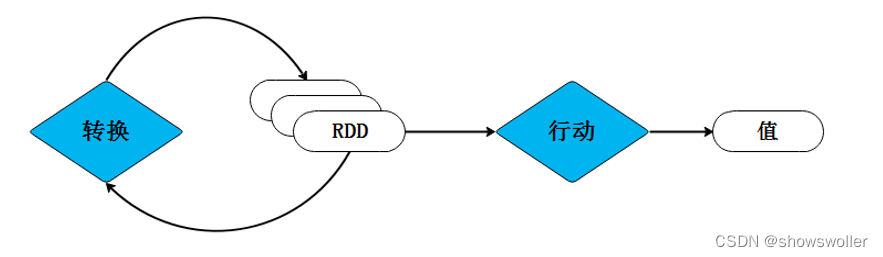
需要源码和数据集请点赞关注收藏后评论区留言私信~~~一、RDD的创建Spark可以从Hadoop支持的任何存储源中加载数据去创建RDD,包括本地文件系统和HDFS等文件系统。我们通过Spark中的SparkContext对象调用textFile()方法加载数据创建RDD。1、从文件系统加载数据创建R...

使用Maven构建Hadoop工程并实现词频统计案例(详细篇)
使用Maven构建Hadoop工程并实现词频统计案例(详细篇)一、实验环境:Hadoop3.1.3IDEACentOS7.5Maven3.6.3伪分布式二、使用Maven构建Hadoop工程1.解压Maven到自己的安装目录tar -zxvf ./apache-maven-3.6.3-bin.tar...

Hadoop基础-05-HDFS项目(词频统计)
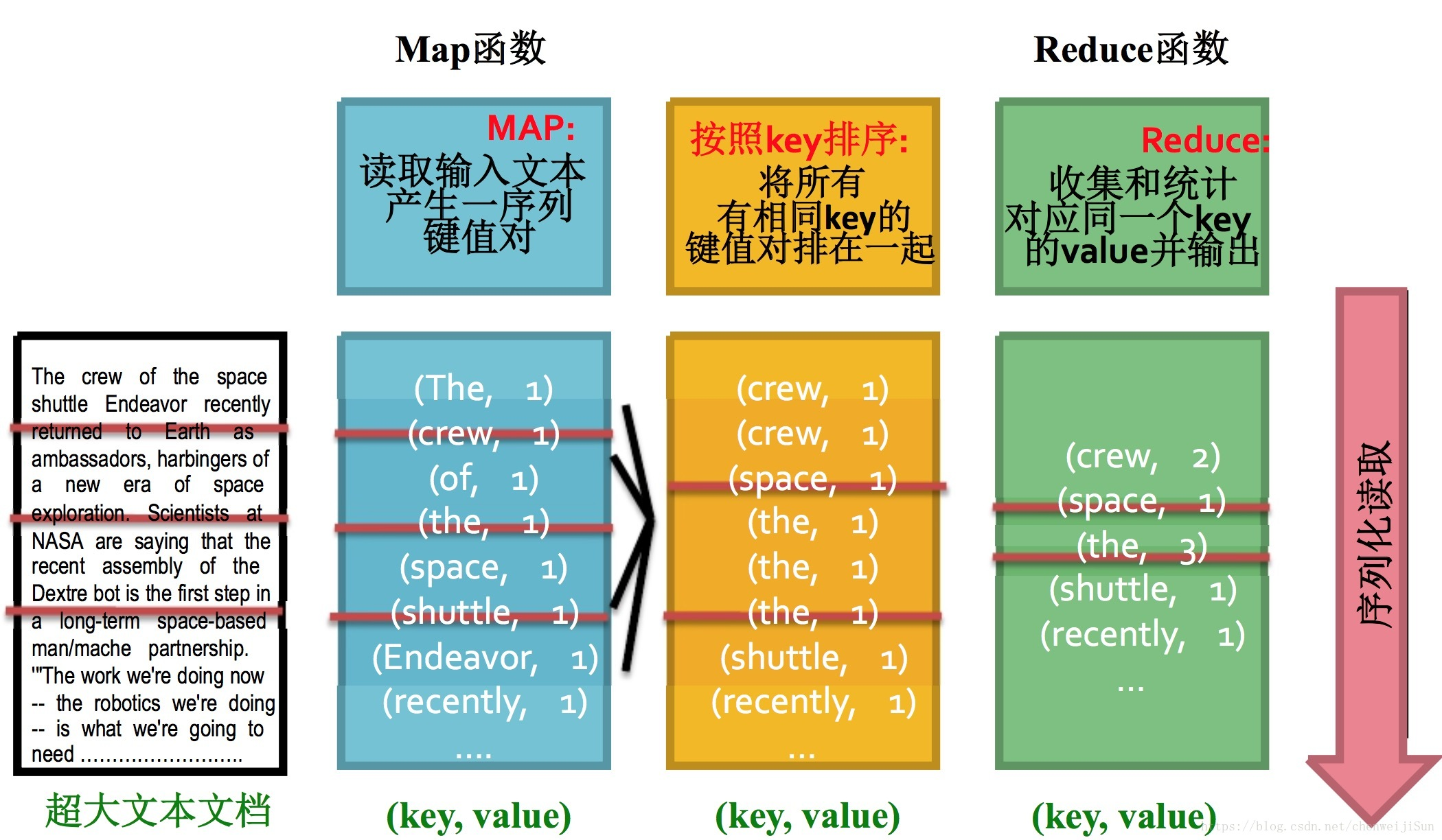
源码见:https://github.com/hiszm/hadoop-trainHDFS项目实战需求分析使用HDFS Java API 才完成HDFS文件系统上的额文件的词频统计例子/test/1.txt==> ' hello world'/test/2.txt==> ' hello ...
Hadoop MapReduce之wordcount(词频统计)
1.创建test.log 点击(此处)折叠或打开 [root@sht-sgmhadoopnn-01 mapreduce]# more /tmp/test.log 1 2 3 a b a v a a ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








