【Hive】所有的Hive任务都会有MapReduce的执行吗?
在 Hive 中,并非所有的任务都会通过 MapReduce 来执行。Hive 作为一种数据仓库查询工具,它在执行查询时会根据查询的特性和底层数据存储的特点选择不同的执行引擎。虽然 MapReduce 是最常见的执行引擎之一,但随着技术的发展和 Hive 自身的优化,还出现了其他的执行引擎,如 Te...

【Hive】Hive的两张表关联,使用MapReduce怎么实现?
在 Hive 中,当两张表进行关联查询时,Hive 会根据查询语句生成对应的 MapReduce 作业来执行查询操作。关联查询的实现通常涉及两个步骤:首先是将查询语句转换成 MapReduce 作业,然后在 Hadoop 集群上执行生成的 MapReduce 作业。在接下来的内容中,我将详细分析如何...

[帮助文档] 使用Hive扩展功能记录数据血缘
E-MapReduce集群默认在Hive服务上集成了EMR-HOOK。EMR-HOOK可以收集作业的SQL信息,例如数据血缘、访问频次等。通过EMR-HOOK,您可以利用数据湖构建(DLF)的数据概况,以统计表和分区的访问次数。同时,您也可以使用DataWorks来管理数据血缘。本文将为您介绍如何配...
[帮助文档] Serverless StarRocks External Catalog
External Catalog(外部数据目录)方便您对接各类外部数据源。通过配置和使用External Catalog,您可以访问并查询存储在外部数据源的数据,无需额外创建外部表。
Hadoop(HDFS+MapReduce+Hive+数仓基础概念)学习笔记(自用)
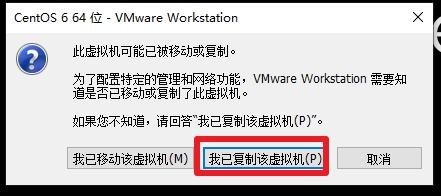
修改虚拟机IP复制网卡的配置第一种方式:配置文件向识别的网卡兼容1、 通过一个主机复制出多个主机2、 开启复制的主机,启动时选择“复制”3、 启动后查看IP ifconfig查看系统识别的网卡Ifconfig -a这里ifconfig看不到IP 是因为系统识别的设备名称与系统配置文件不同导致。配置文...
[帮助文档] 如何使用Hive连接器
使用Hive连接器可以查询和分析存储在Hive数据仓库中的数据。本文为您介绍Hive连接器相关的内容和操作。
[帮助文档] Hive中查询FlinkTableStore中的数据
E-MapReduce的Flink Table Store服务支持在Hive中查询数据。本文通过示例为您介绍如何在Hive中查询Flink Table Store中的数据。
[帮助文档] 如何在Hive中使用Paimon
E-MapReduce支持在Hive中查询Paimon数据。本文通过示例为您介绍如何在Hive中查询Paimon中的数据。
如果对一个hive表修改,阿里云E-MapReduce现在用的是上面的v2版本吗?
如果一个hive表修改location至'oss://test-hadoop-emr/sr/' 直接写入到oss,阿里云E-MapReduce现在用的是上面的v2版本吗? https://www.modb.pro/db/183904
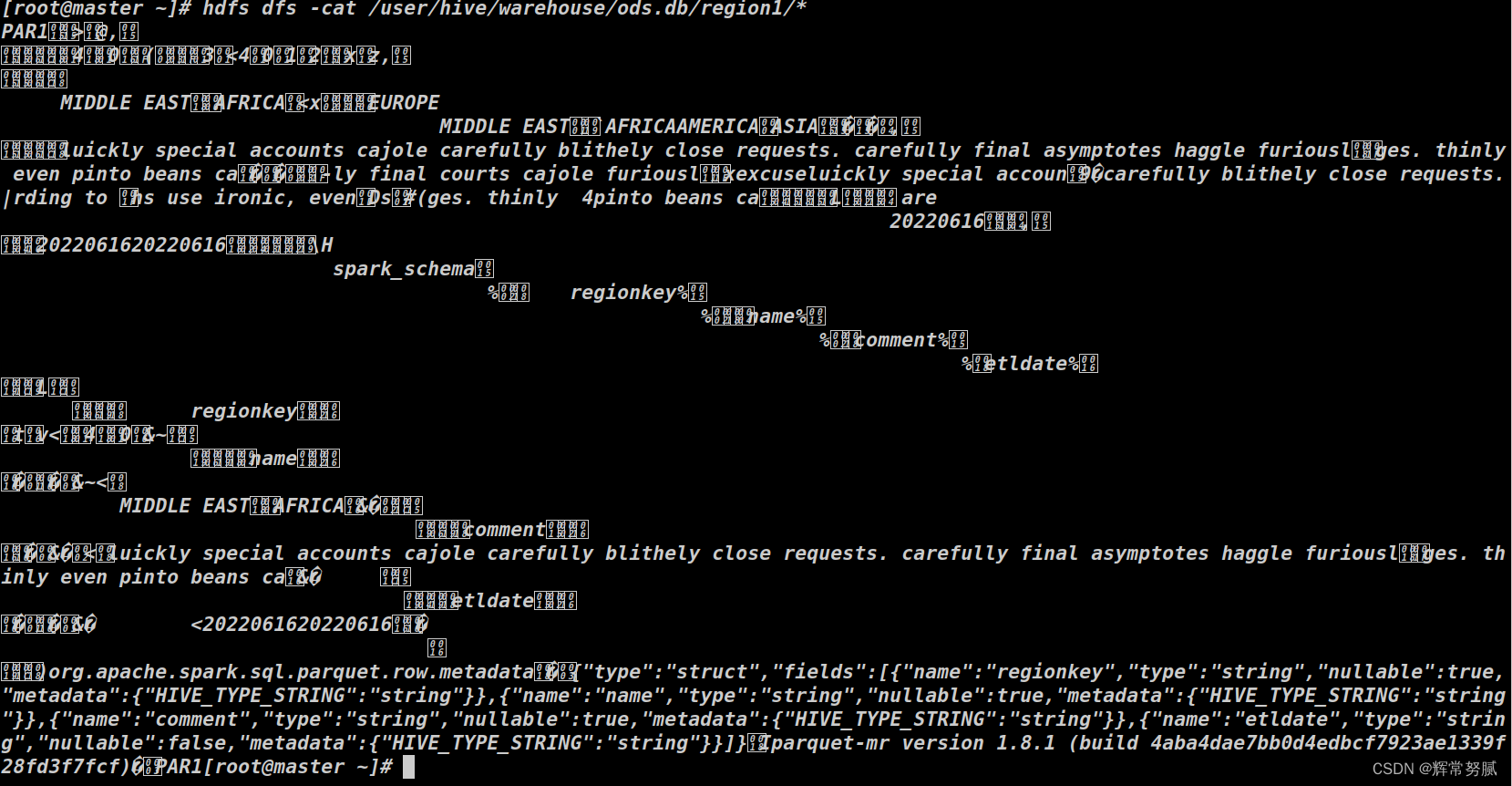
HADOOP MapReduce 处理 Spark 抽取的 Hive 数据【解决方案一】
开端:今天咱先说问题,经过几天测试题的练习,我们有从某题库中找到了新题型,并且成功把我们干趴下,昨天今天就干了一件事,站起来。沙问题?java mapeduce 清洗 hive 中的数据 ,清晰之后将driver代码 进行截图提交。坑号1: spark之前抽取的数据是.parquet格.....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。