数据仓库的Hive的概念一款构建在Hadoop之上的数据仓库
构建在Hadoop之上的数据仓库:HiveHive是一款基于Hadoop的数据仓库系统,它可以将结构化数据存储在Hadoop的HDFS中,并使用SQL语言进行查询和分析。Hive的目的是让用户可以使用熟悉的SQL语言来处理大规模的结构化数据,而无需熟悉MapReduce编程。数据存储Hive将数据存...
[帮助文档] 如何将Hive数据导入AnalyticDB MySQL湖仓
云原生数据仓库AnalyticDB MySQL版湖仓版(3.0)支持通过Hive数据迁移将Hive数据迁移至OSS。本文介绍如何添加Hive数据源,新建Hive迁移链路并启动任务,以及数据迁移后如何进行数据分析和管理数据迁移任务。


「大数据系列」:Apache Hive 分布式数据仓库项目介绍
Apache Hive™数据仓库软件有助于读取,编写和管理驻留在分布式存储中的大型数据集并使用SQL语法进行查询Hive 特性Hive构建于Apache Hadoop™之上,提供以下功能:通过SQL轻松访问数据的工具,从而实现数据仓库任务,如提取/转换/加载(ETL),报告和数据分析。...
数据仓库 Hive 从入门到大神(五)
数据仓库 Hive 从入门到大神(五)在这一篇文章中,我们将继续介绍 Hive 的高级概念和用法。分区表分区表是在建表时指定了一个或多个分区键的表。Hive 中的分区允许您对数据进行逻辑上的划分,以便更轻松地查询和管理数据。例如,如果您有一个包含销售数据的表,并且您希望按年份、月份和日期对该表进行分...
数据仓库 Hive 从入门到大神(四)
数据仓库 Hive 从入门到大神(四)分区和桶在大规模数据处理场景下,对数据进行分区和桶操作可以提高查询效率。Hive 提供了分区和桶功能,可以根据表的特点对数据进行优化存储和查询。分区分区是将表按照一定的规则划分为多个子目录来存储,例如按照时间、地域或者用户等字段进行分区。通过分区,我们可以快速地...
数据仓库 Hive 从入门到大神(三)
数据仓库 Hive 从入门到大神(三)自定义函数和UDF在 Hive 中,我们可以自定义函数和 UDF(User Defined Function),以满足不同的业务需求。下面分别介绍它们的概念和用法。自定义函数自定义函数是指由用户编写的 Hive 函数,可以使用 Java 或 Python 等编程...
数据仓库 Hive 从入门到大神(二)
数据仓库 Hive 从入门到大神(二)表的创建和管理在 Hive 中,表是一个很重要的概念。我们可以通过 CREATE TABLE 语句来创建表,例如:CREATE TABLE students ( id INT, name STRING, age INT ) ROW FORMAT DELIMITE...
数据仓库 Hive 从入门到大神(一)
数据仓库 Hive 从入门到大神(一)随着大数据时代的到来,数据处理和分析变得越来越重要。在海量数据中提取有价值的信息和洞见,需要使用高效、稳定、可扩展的数据仓库。Hive作为一种基于Hadoop的数据仓库,在大数据领域得到了广泛应用和认可。笔者写的本系列文章将介绍Hive的原理、安装、配置和使用方...
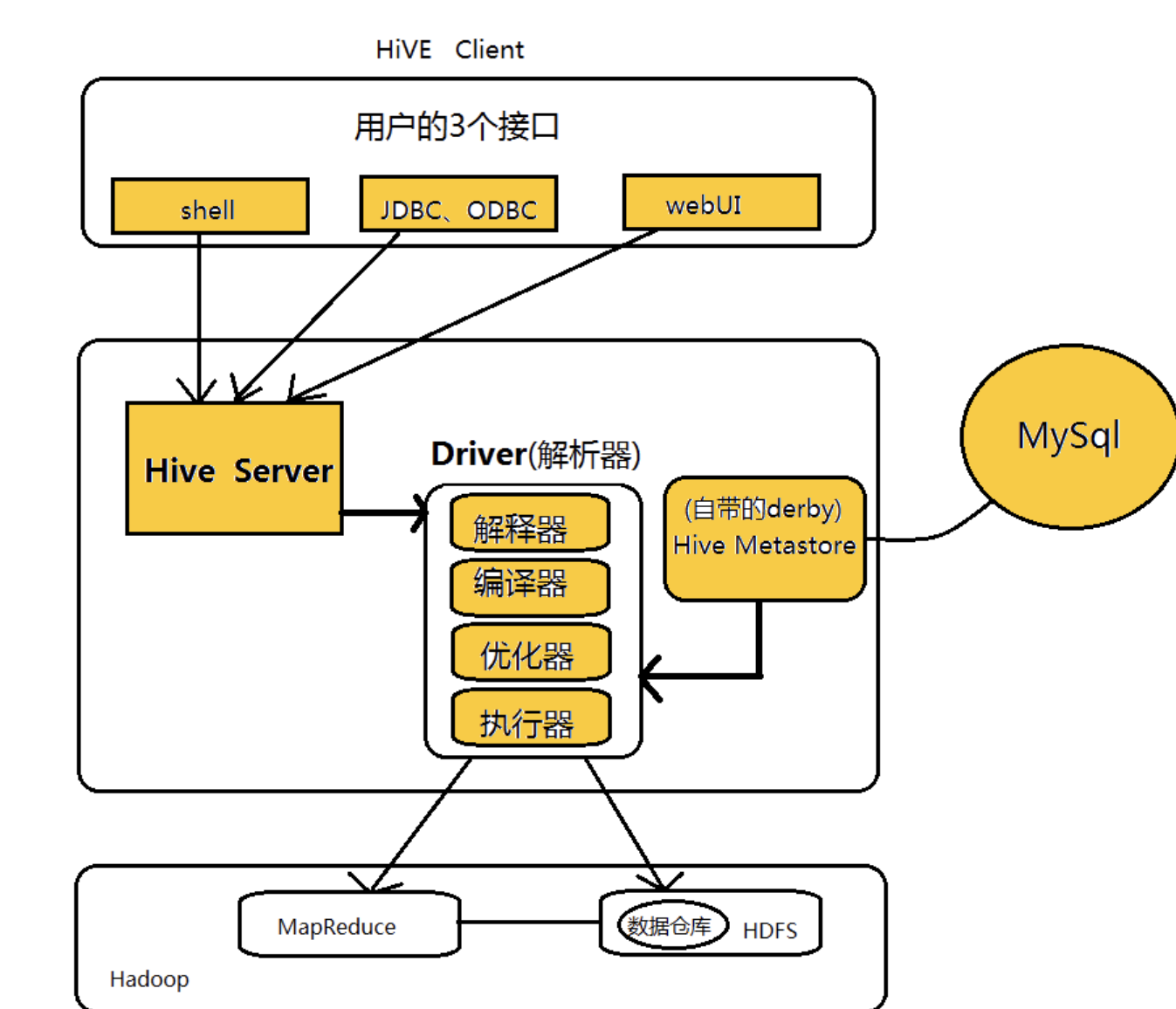
Hive数据仓库-概念
数据仓库基础理论HDFS经理 管理1oo台机器,提供一个接口(数据存储)HIVE在hadup进行结构化数据处理的解决方案Spark基于内存计算快 Maprdeues 100倍概念数据仓库是一个用于存储,分析,报告的数据系统数据仓库本身不生产任何数据不需要消费任何数据,其结果开放给各个外部应用实例数据...

大数据开发笔记(四):Hive数据仓库
Hive思维导图Hive介绍Hive主要解决海量结构化日志的数据统计分析,它是hadoop上的一种数据仓库工具,可以将结构化的数据文件映射成一张表,并提供类似于SQL的查询方式,本质上来说是将Hive转化成MR程序。Hive与其它数据库的区别Hive数据是存储在HDFS,本质上是转换成mr程序执行,...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。