[帮助文档] 迁移Hadoop集群至DataLake集群
本文将详细阐述如何将您已有的旧版数据湖集群(Hadoop),高效地迁移至数据湖集群(DataLake),以下分别简称“旧集群”和“新集群”。迁移过程将充分考虑旧集群的版本、元数据类型以及存储方式,并针对这些因素,提供适应新集群的迁移策略与步骤。
[帮助文档] 如何管理SmartDataHadoop回收站
Hadoop回收站是Hadoop文件系统的重要功能,可以恢复误删除的文件和目录。本文为您介绍Hadoop回收站的使用方法。

[帮助文档] 如何管理HDFSHadoop回收站
Hadoop回收站是Hadoop文件系统的重要功能,可以恢复误删除的文件和目录。本文为您介绍Hadoop回收站的使用方法。
[帮助文档] 如何管理OSS/OSS-HDFSHadoop回收站
Hadoop回收站是Hadoop文件系统的重要功能,可以恢复误删除的文件和目录。本文为您介绍Hadoop回收站的使用方法。
[帮助文档] 如何通过HadoopShell命令访问OSS和OSS-HDFS
本文为您介绍如何通过Hadoop Shell命令访问OSS和OSS-HDFS。
从hadoop到云原生,大数据平台如何做存放分离
Hadoop 的诞生改变了企业对数据的存储、处理和分析的过程,加速了大数据的发展,受到广泛的应用,给整个行业带来了变革意义的改变;随着云计算时代的到来, 存算分离的架构受到青睐,企业开开始对 Hadoop 的架构进行改造。今天与大家一起简单回顾 Hadoop 架构以及目前市面上不同的存算分离的架构方...

在本地利用虚拟机搭建Hadoop大数据平台
一、 虚拟机备份:注意:VM虚拟机并不是一个非常稳定的系统,在虚拟化情况下,有时候会出现一些非常莫名奇妙的错误,这就需要我们有足够的克隆备份,以用于错误出现的恢复和追溯,大家可以参考我的虚拟机建设方式。在基础平台中,一般都有一些搭建好的基础组件,例如我们在Hadoop...
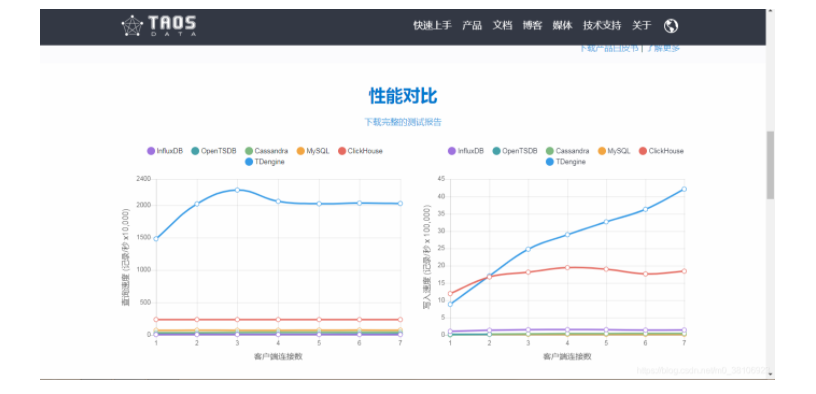
GitHub开源比Hadoop快至少10倍的物联网大数据平台
TDengine是一个开源的专为物联网、车联网、工业互联网、IT运维等设计和优化的大数据平台。除核心的快10倍以上的时序数据库功能外,还提供缓存、数据订阅、流式计算等功能,最大程度减少研发和运维的工作量。7月12号,淘思数据创始人陶建辉对外正式宣布TDengine, 一款专为物联网定制打造的大数据平...
武汉做Hadoop大数据平台的企业有哪些?
Hadoop大数据平台
如何搭建Hadoop金融机构大数据平台?需要注意什么问题?
大数据在金融领域的作用
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








