Redis 实战篇:巧用数据类型实现亿级数据统计
在移动应用的业务场景中,我们需要保存这样的信息:一个 key 关联了一个数据集合,同时还要对集合中的数据进行统计排序。常见的场景如下:给一个 userId ,判断用户登陆状态;两亿用户最近 7 天的签到情况,统计 7 天内连续签到的用户总数;统计每天的新增与第二天的留存用户数;统计网站的对访客(Un...
[帮助文档] 云数据库Redis版数据类型及功能特性的使用限制
您可以在本文中查看云数据库 Redis 版各数据类型以及部分功能特性的使用限制。

实战!Redis 巧用数据类型实现亿级数据统计!
基数统计网站的 UV排序统计最新评论列表排行榜聚合统计交集-共同好友差集-每日新增好友数并集-总共新增好友小结在移动应用的业务场景中,我们需要保存这样的信息:一个 key 关联了一个数据集合,同时还要对集合中的数据进行统计排序。常见的场景如下:给一个 userId ,判断用户登陆状态;两亿用户最近 ...
Redis 实战篇:巧用数据类型实现亿级数据统计 (三)
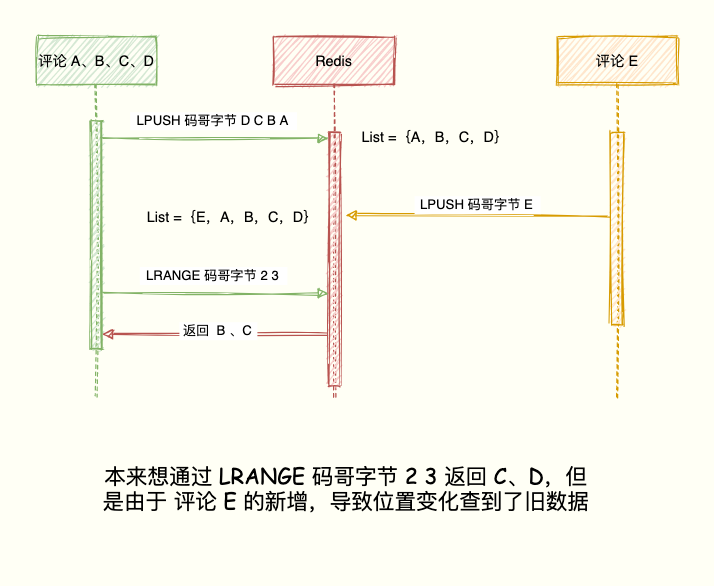
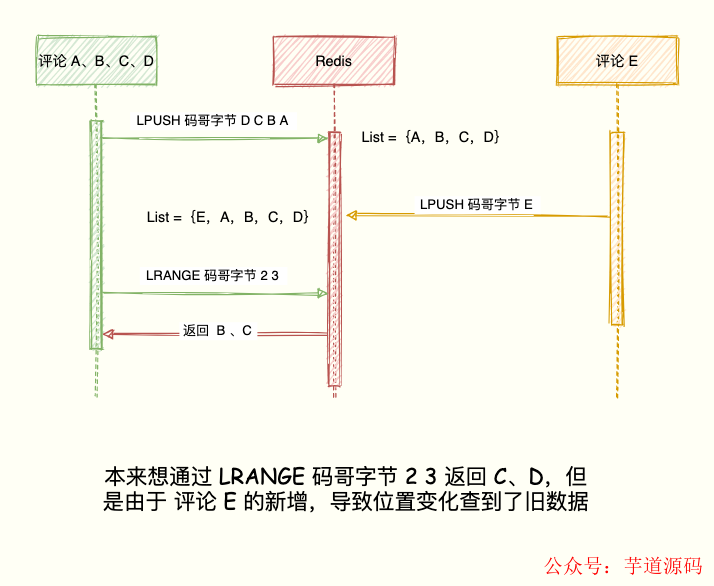
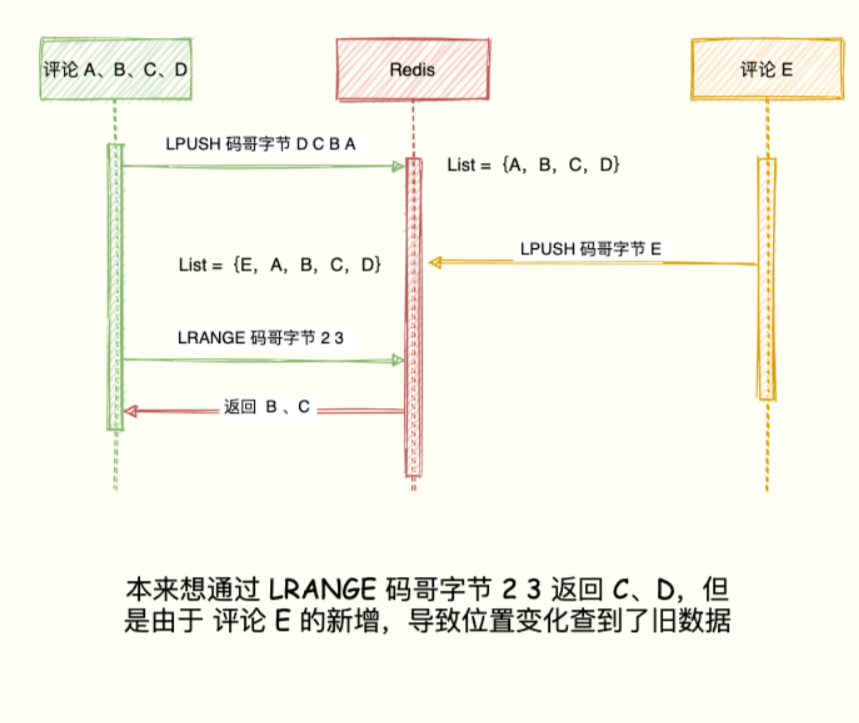
排行榜码老湿,对于最新列表的场景,List 和 Sorted Set 都能实现,为啥还用 List 呢?直接使用 Sorted Set 不是更好,它还能设置 score 权重排序更加灵活。原因是 Sorted Set 类型占用的内存容量是 List 类型的数倍之多,对于列表数量不多的情况,可以用 S...
Redis 实战篇:巧用数据类型实现亿级数据统计 (二)
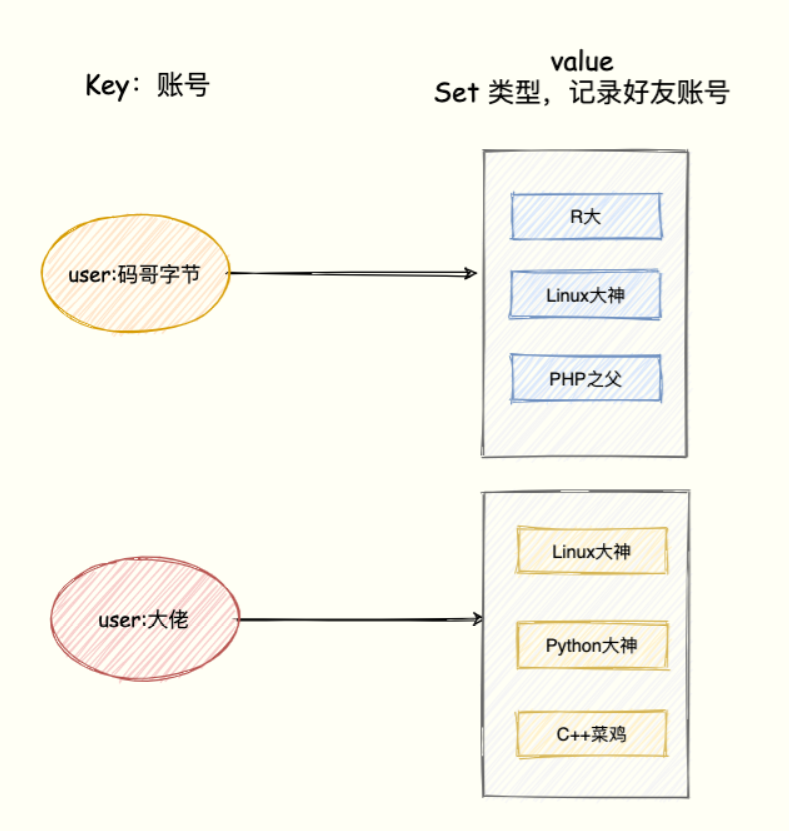
基数统计基数统计:统计一个集合中不重复元素的个数,常见于计算独立用户数(UV)。实现基数统计最直接的方法,就是采用集合(Set)这种数据结构,当一个元素从未出现过时,便在集合中增加一个元素;如果出现过,那么集合仍保持不变。当页面访问量巨大&#x...

Redis 实战篇:巧用数据类型实现亿级数据统计 (一)
常见的场景如下:给一个 userId ,判断用户登陆状态;两亿用户最近 7 天的签到情况,统计 7 天内连续签到的用户总数;统计每天的新增与第二天的留存用户数;统计网站的对访客(Unique Visitor,UV)量最新评论列表根据播放量音乐榜单通常情况下,...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









云数据库 Redis 版数据类型相关内容
- 云数据库 Redis 版入门数据类型
- 云数据库 Redis 版配置文件数据类型
- 云数据库 Redis 版数据类型应用
- 云数据库 Redis 版数据类型优化
- 云数据库 Redis 版数据类型bitmaps
- 云数据库 Redis 版数据类型list set
- 云数据库 Redis 版数据类型string hash
- 云数据库 Redis 版学习数据类型string
- 云数据库 Redis 版数据类型set
- 云数据库 Redis 版数据类型hash
- 云数据库 Redis 版数据类型string
- 云数据库 Redis 版数据类型list
- 云数据库 Redis 版数据类型命令
- 云数据库 Redis 版实战篇数据类型数据统计
- 云数据库 Redis 版数据类型对象
- 云数据库 Redis 版数据类型hyperloglog
- 云数据库 Redis 版数据类型使用手册
- 云数据库 Redis 版数据类型bitmap
- 云数据库 Redis 版数据类型zset
- 云数据库 Redis 版数据类型bitmaps hyperloglog geo
- 云数据库 Redis 版数据类型使用场景
- 云数据库 Redis 版数据类型sorted
- 云数据库 Redis 版数据类型策略
- 云数据库 Redis 版简介数据类型
- 云数据库 Redis 版数据类型实战
- 云数据库 Redis 版string数据类型应用场景
- 云数据库 Redis 版数据类型常用命令
- 集合云数据库 Redis 版数据类型
- 云数据库 Redis 版list数据类型
- 云数据库 Redis 版数据类型基本操作
- 云数据库 Redis 版常用命令数据类型
- 云数据库 Redis 版数据类型geospatial
- 云数据库 Redis 版数据类型操作命令
- 云数据库 Redis 版数据类型实现原理
- 云数据库 Redis 版数据类型字符串列表
- go云数据库 Redis 版数据类型
- the-way-to-go云数据库 Redis 版数据类型
- 云数据库 Redis 版数据类型集合
- 云数据库 Redis 版学习数据类型拓展
- 面试云数据库 Redis 版数据类型
- 云数据库 Redis 版笔记数据类型
- 云数据库 Redis 版特殊数据类型
- 云数据库 Redis 版特殊数据类型bitmap
- 云数据库 Redis 版数据类型学习笔记
- 云数据库 Redis 版特殊数据类型hyperloglog基数统计
- 云数据库 Redis 版特殊数据类型geospatial
- 云数据库 Redis 版数据类型哈希hash
- 面试数据类型云数据库 Redis 版
云数据库 Redis 版更多数据类型相关
云数据库 Redis 版您可能感兴趣
- 云数据库 Redis 版开发
- 云数据库 Redis 版最佳实践
- 云数据库 Redis 版Key
- 云数据库 Redis 版过期
- 云数据库 Redis 版前端
- 云数据库 Redis 版绝佳
- 云数据库 Redis 版简记
- 云数据库 Redis 版主从复制
- 云数据库 Redis 版分布式
- 云数据库 Redis 版分布式锁
- 云数据库 Redis 版集群
- 云数据库 Redis 版安装
- 云数据库 Redis 版缓存
- 云数据库 Redis 版实现
- 云数据库 Redis 版配置
- 云数据库 Redis 版数据
- 云数据库 Redis 版命令
- 云数据库 Redis 版持久化
- 云数据库 Redis 版Springboot
- 云数据库 Redis 版操作
- 云数据库 Redis 版原理
- 云数据库 Redis 版MySQL
- 云数据库 Redis 版java
- 云数据库 Redis 版实战
- 云数据库 Redis 版数据结构
- 云数据库 Redis 版spring
- 云数据库 Redis 版连接