[帮助文档] 调用GetSparkSQLEngineState查询SparkSQL引擎状态
查询Spark SQL引擎的状态。
[帮助文档] 调用KillSparkSQLEngine关闭SparkSQL引擎
关闭Spark SQL引擎。

[帮助文档] 如何在Spark3服务中开启Native引擎,有哪些限制
本文为您介绍Spark Native引擎在使用过程中的限制,以及如何在Spark3服务中开启Native引擎。
继Spark之后,UC Berkeley 推出新一代高性能深度学习引擎——Ray(2)
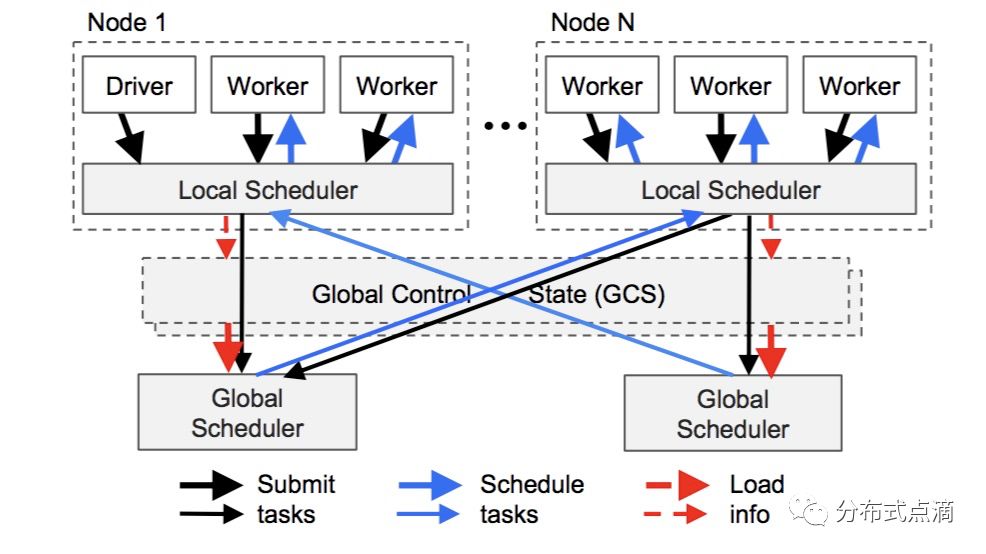
应用层应用层包括三种类型的进程:驱动进程(Driver):用来执行用户程序。工作进程(Worker):用来执行 Driver 或者其他 Worker 指派的任务(remote functions,就是用户代码中装饰了`@ray.remote` 的那些函数)的无状...
继Spark之后,UC Berkeley 推出新一代高性能深度学习引擎——Ray(1)
导读继 Spark 之后,UC Berkeley AMP 实验室又推出一重磅高性能AI计算引擎——Ray,号称支持每秒数百万次任务调度。那么它是怎么做到的呢?在试用之后,简单总结一下:极简 Python API 接口:在函数或者类定义时加上 ray.remote 的装饰器并做一些微小改变,...
[帮助文档] 测试数据湖分析DLASpark引擎的方法
本次测试采用3种不同的测试场景,针对开源自建的Hadoop+Spark集群与阿里云云原生数据湖分析DLA Spark在执行Terasort基准测试的性能做了对比分析。您可以按照本文介绍自行测试对比,快速了解云原生数据湖分析(DLA)Spark引擎的性价比数据。
大数据和AI | 基于Spark的高性能向量化查询引擎
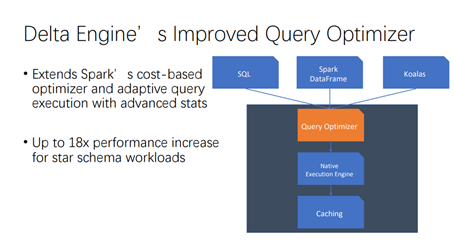
嘉宾:范文臣Databricks 开源组技术主管,Apache Spark Committer、PMC成员,Spark开源社区核心开发之一。 视频地址:https://developer.aliyun.com/live/245461正文:Databricks最新开发的一款基于Spark的高性能向量化...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark产品
- apache spark k8s
- apache spark深度学习
- apache spark集群
- apache spark分析
- apache spark数据
- apache spark数据库
- apache spark可视化分析
- apache spark决策
- apache spark可视化
- apache spark SQL
- apache spark streaming
- apache spark Apache
- apache spark Hadoop
- apache spark大数据
- apache spark rdd
- apache spark MaxCompute
- apache spark运行
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark任务
- apache spark程序