JAVA网络爬虫之Jsoup解析
最近有个项目任务是爬取汽车之家上面各论坛的回复。但是大家都清楚汽车之家的反爬虫措施做得相当好。也是为了保护个人权益的原因或者是保护用户的信息吧。所以为了完成任务就必须要反反爬虫。这是一个很让人头痛的问题。所以这里我准备使用jsoup来爬取, jsoup是一款Java 的HTML解析器,可直接解析某个...
Python爬虫:scrapy内置网页解析库parsel-通过css和xpath解析xml、html
文档https://pypi.org/project/parsel/https://github.com/scrapy/parsel安装pip install parsel代码示例from parsel import Selector selector = Selector(text="""<...

从零开始学爬虫4——解析
本文为学习笔记,原教程:https://www.bilibili.com/video/BV1Db4y1m7Ho/?spm_id_from=333.999.0.0&vd_source=4cfa97d709226c94ec1c02fc78b760ec1 xpath1. xpath插件的安装打开c...
「Python」爬虫-2.xpath解析和cookie,session
持续创作,加速成长!这是我参与「掘金日新计划 · 10 月更文挑战」的第15天, 点击查看活动详情前言本文主要介绍爬虫知识中的xpath解析以及如何处理cookies,将配合两个案例-视频爬取和b站弹幕爬取分别讲解。如果对爬虫的整体思维(确定目标网址 -> 请求该网址 ->读取...
Java爬虫:Jsoup解析HTML
官网:https://jsoup.org/依赖<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.13.1<...
Python爬虫:使用newspaper解析新闻页面信息
github: https://github.com/codelucas/newspaper安装pip3 install newspaper3k代码示例# -*- coding: utf-8 -*- from newspaper import Article url = "https://news....
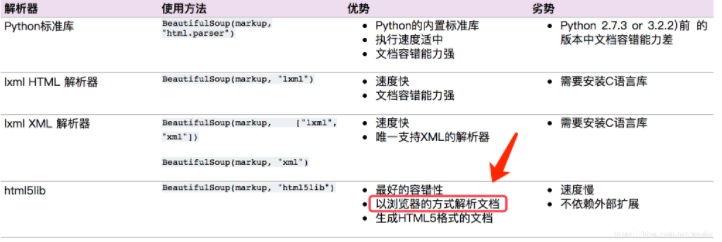
Python爬虫:scrapy利用html5lib解析不规范的html文本
问题当爬取表格(table) 的内容时,发现用 xpath helper 获取正常,程序却解析不到在chrome、火狐测试都有这个情况。出现这种原因是因为浏览器会对html文本进行一定的规范化scrapy 使用的解析器是 lxml ,下面使用lxml解析,只是函数表达不一样,xpath和css选择器...
Python爬虫:使用lxml解析网页内容
安装pip install lxml代码示例from lxml import etree text = """ <html> <head> <title>这是标题</title> </head> <body> <div&g...
Python爬虫:Scrapy链接解析器LinkExtractor返回Link对象
LinkExtractorfrom scrapy.linkextractors import LinkExtractor Linkfrom scrapy.link import LinkLink四个属性url text fragment nofollow 如果需要解析出文本,需要在 LinkExtr...
Python爬虫:chrome网页解析工具-XPath Helper
非常棒的东西介绍:xPath helper是一款Chrome浏览器的开发者插件作用:通过xPath语法轻松获取HTML元素安装:1. chrome应用商店2. chrome插件网(http://www.cnplugins.com/)使用:Ctrl + Shift + X 激活再次按Ctrl-Shif...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








