Hadoop基础学习---5、MapReduce概述和WordCount实操(本地运行和集群运行)、Hadoop序列化
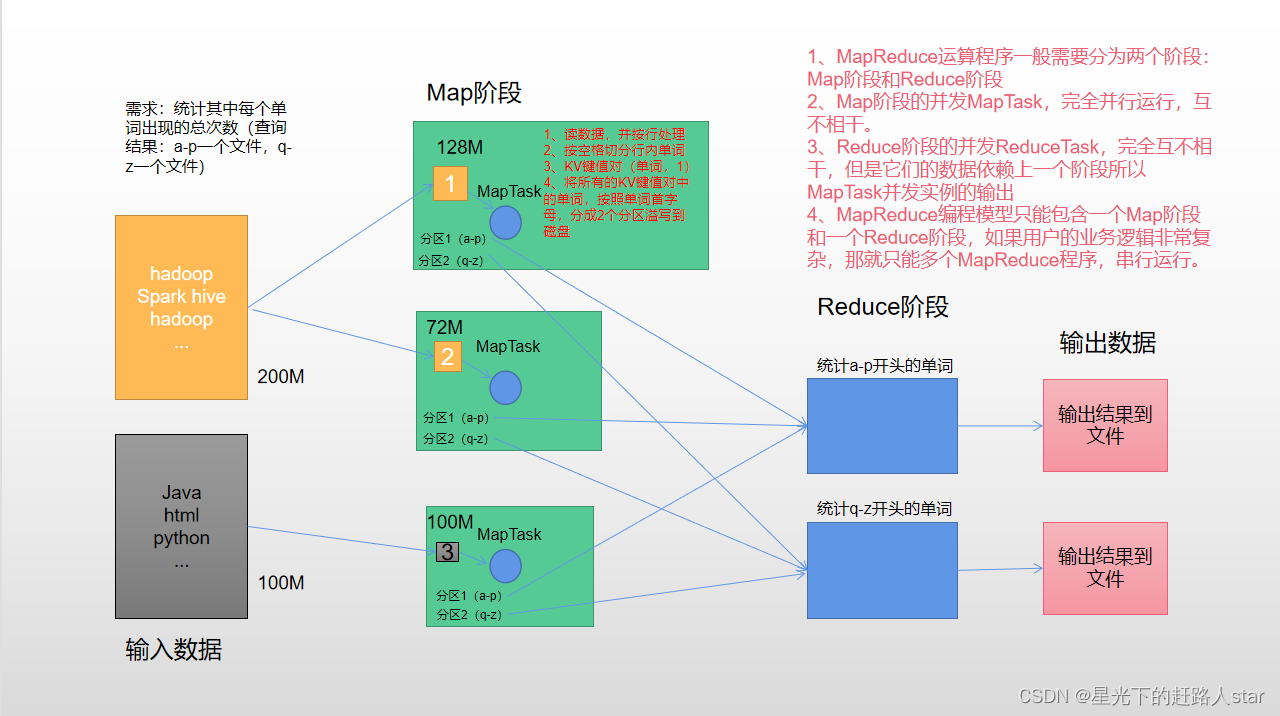
1、MapReduce概述1.1 MapReduce定义MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。1.2...
[帮助文档] 如何在EMR的Hadoop集群中运行Spark作业对接DataHub数据_EMR on ECS_开源大数据平台 E-MapReduce(EMR)
本文介绍如何在E-MapReduce的Hadoop集群,运行Spark作业消费DataHub数据、统计数据个数并打印出来。


【大数据】Linux下安装Hadoop(2.7.1)详解及WordCount运行
在完成了Storm的环境配置之后,想着鼓捣一下Hadoop的安装,网上面的教程好多,但是没有一个特别切合的,所以在安装的过程中还是遇到了很多的麻烦,并且最后不断的查阅资料,终于解决了问题,感觉还是很好的,下面废话不多说,开始进入正题。 本机器的配置环境如下:...
Hadoop集群(第6期)_WordCount运行详解
1、MapReduce理论简介 1.1 MapReduce编程模型 MapReduce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单地说,MapReduce就是"任务的分解与结果的汇总"...
Hadoop入门之WordCount运行详解
原文:http://www.cnblogs.com/xia520pi/archive/2012/05/16/2504205.html 虾皮工作室:赠人玫瑰,手留余香。 http://www.xiapistudio.com/
Hadoop MapReduce如何进行WordCount自主编译运行
上次我们已经搭建了Hadoop的伪分布式环境,并且运行了一下Hadoop自带的例子–WordCount程序,展现良好。但是大多数时候还是得自己写程序,编译,打包,然后运行的,所以做一次自编译打包运行的实验。 编辑程序 在Eclipse或者NetBeans中编辑WordCount.java程序,用ID...
《Hadoop与大数据挖掘》一2.4.3 动手实践:编写Word Count程序并打包运行
本节书摘来华章计算机《Hadoop与大数据挖掘》一书中的第2章 ,第2.4.3节,张良均 樊 哲 位文超 刘名军 许国杰 周 龙 焦正升 著 更多章节内容可以访问云栖社区“华章计算机”公众号查看。 2.4.3 动手实践:编写Word Count程序并打包运行 1)打开Eclipse,新建MapRed...
hadoop:将WordCount打包成独立运行的jar包
hadoop示例中的WordCount程序,很多教程上都是推荐以下二种运行方式: 1.将生成的jar包,复制到hadoop集群中的节点,然后运行 $HADOOP_HOME/bin/hadoop xxx.jar xxx.WordCount /input/xxx.txt /output 2.或者直接在I...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








