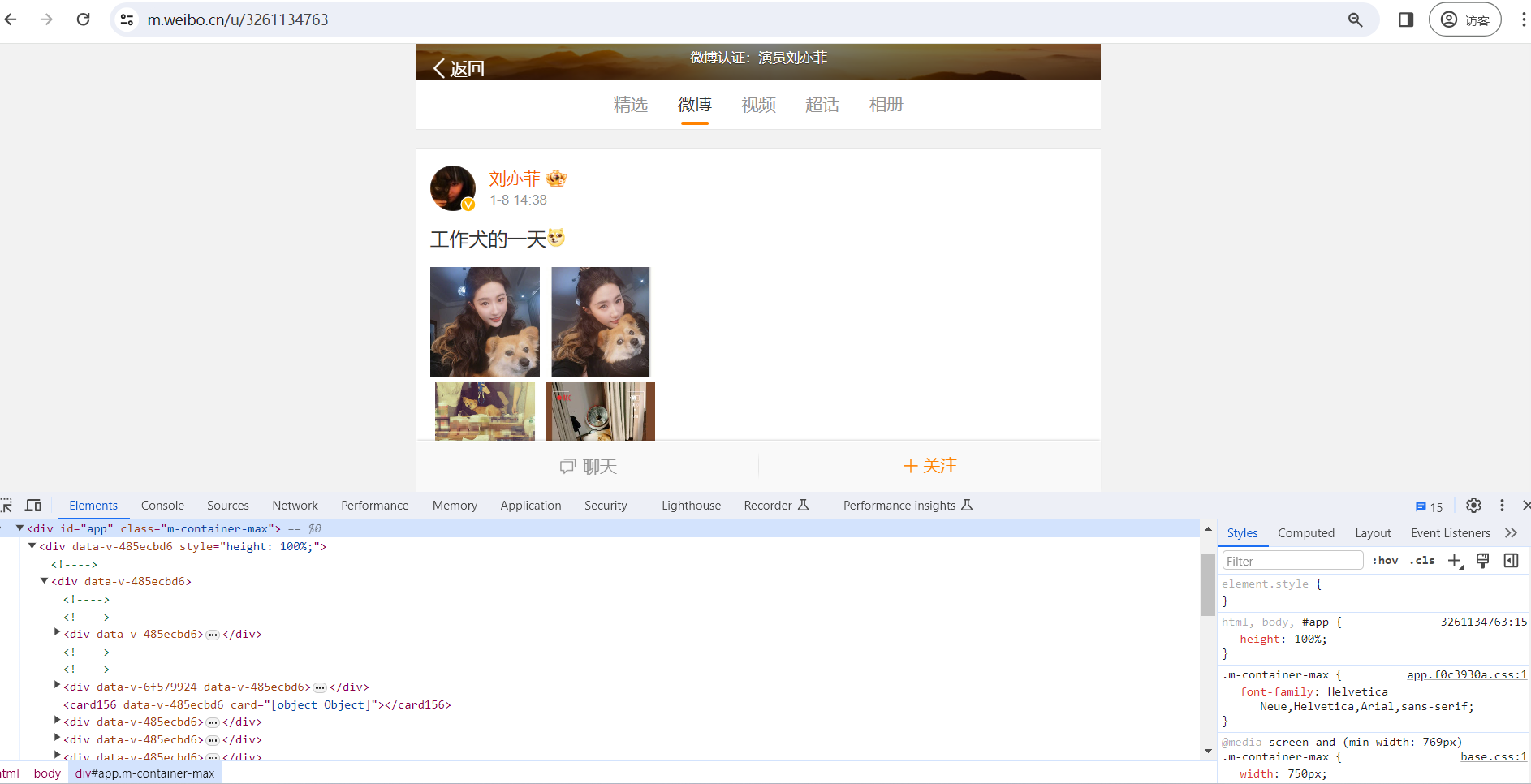
Python爬虫之Ajax分析方法与结果提取#6
Ajax 分析方法 这里还以前面的微博为例,我们知道拖动刷新的内容由 Ajax 加载,而且页面的 URL 没有变化,那么应该到哪里去查看这些 Ajax 请求呢? 1. 查看请求 这里还需要借助浏览器的开发者工具,下面以 Chrome 浏览器为例来介绍。 首先,用 Chrome 浏览器打开微博的链接 ...
Python爬虫:实现爬取、下载网站数据的几种方法
使用脚本进行下载的需求很常见,可以是常规文件、web页面、Amazon S3和其他资源。Python 提供了很多模块从 web 下载文件。下面介绍 一、使用 requests requests 模块是模仿网页请求的形式从一个URL下载文件 示例代码: import requests url = 'x...


简单而高效:使用PHP爬虫从网易音乐获取音频的方法
概述 网易音乐是一个流行的在线音乐平台,提供了海量的音乐资源和服务。如果你想从网易音乐下载音频文件,你可能会遇到一些困难,因为网易音乐对其音频资源进行了加密和防盗链的处理。本文将介绍一种使用PHP爬虫从网易音乐获取音频的方法,该方法简单而高效,只需几行代码就可以实现。 正文 步骤一:获取音频ID 要...
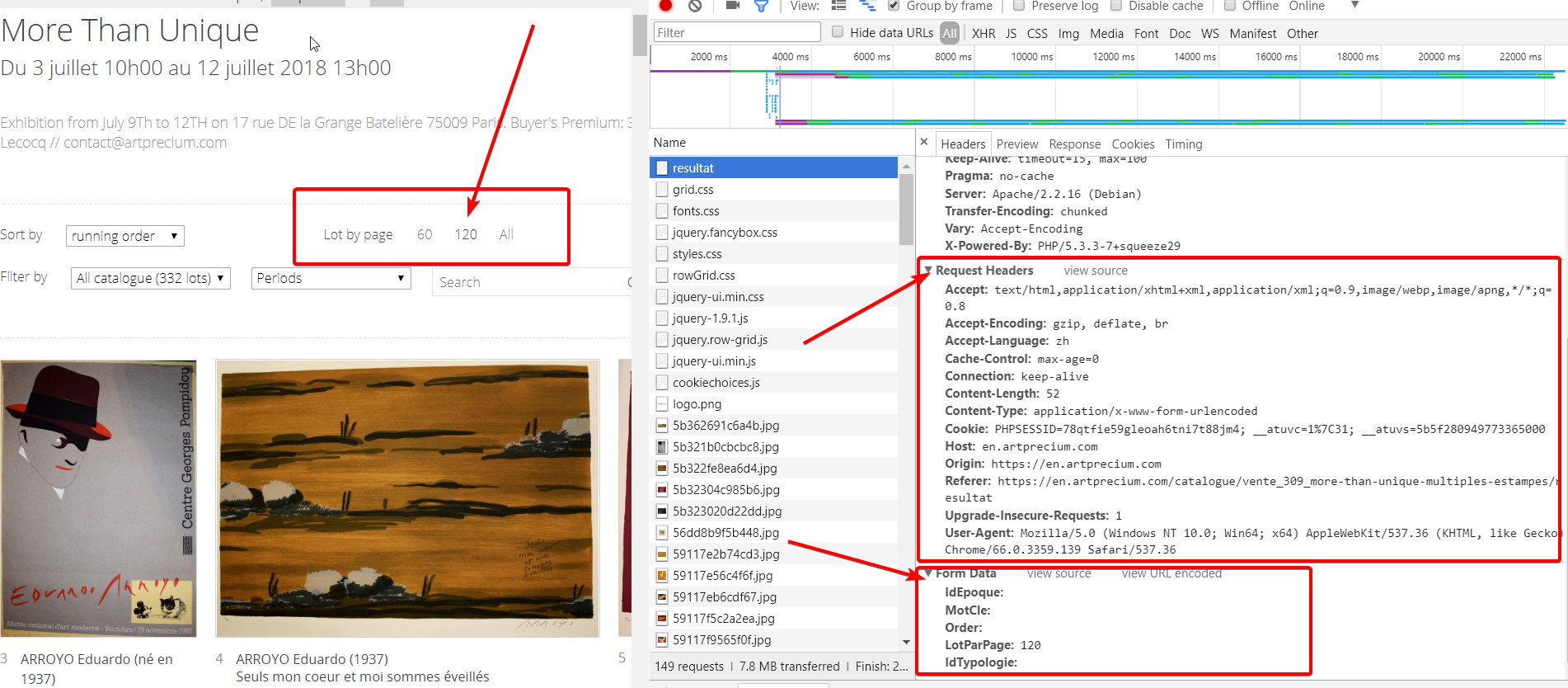
Python爬虫中:get和post方法使用
requests库是一个常用于http请求的模块,性质是和urllib,urllib2是一样的,作用就是向指定目标网站的后台服务器发起请求,并接收服务器返回的响应内容。1. 安装requests库使用pip install requests安装如果再使用pip安装python模块出现timeout超...
爬虫识别-main 方法及封装 processData 总结|学习笔记
开发者学堂课程【大数据实战项目:反爬虫系统(Lua+Spark+Redis+Hadoop 框架搭建)第五阶段:爬虫识别-main 方法及封装 processData 总结】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun...

爬虫第一次笔记 urllib的基本使用 urllib一个类型,六个方法 urllib下载 urllib请求对象的定制
urllib的基本使用使用urllib获取百度首页的源码# 1. 定义一个url (指的就是要访问的地址) url = "http://www.baidu.com" # 2. 模拟浏览器向服务器发送请求 response = urllib.request.urlopen(url) # 3. 获取响应...
Python爬虫:xpath常用方法示例
# -*-coding:utf-8-*- html = """ <html> <head> <base href='http://example.com/' /> <title>Example website</title> </he...
python爬虫的方法有哪些?
python爬虫的方法有哪些?
python爬虫的好方法都有哪些
python爬虫的好方法都有哪些
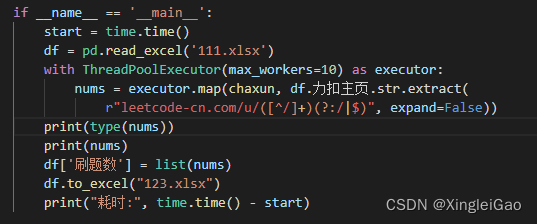
【从零开始的python生活②】力扣爬虫改进方法(2)
四、多线程请求信息此处感谢明佬的指导,省了不少麻烦事@小小明-代码实体首先介绍一下ThreadPoolExecutor线程库:导入:from concurrent.futures import ThreadPoolExecutor创建线程库:with ThreadPoolExecutor(max_w...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子


最佳实践


